1. top 查看节点资源使用率超过 100%
| |
这是由于在计算使用率时,默认使用的是可分配的资源,排除了 Kubelet 保留的部分。在 kubectl 源码中可以看到:
| |
如果需要查看节点总的资源使用情况,可添加 --show-capacity 参数:
| |
实际上 Allocatable 和 Capacity 在节点对象上可以直接看到:
| |
在 Kubelet 的配置文件 /var/lib/kubelet/config.yaml 或者启动命令参数 --system-reserved=cpu=1,memory=2Gi --kube-reserved=cpu=1,memory=2Gi 可以查看具体的资源预留额度。详情可以参考 https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/reserve-compute-resources/ 。
Allocatable = Capacity - Reserved - Evicted Threshold(驱逐容忍度),其中 Evicted Threshold 根据不同资源,通常为一个很小的数值或比例。
2. top node 与 Grafana 数据不一致
2.1 free 与 node_memory_Mem 同源
使用 free 查看节点资源使用情况如下:
| |
Grafana 节点资源使用情况如下:
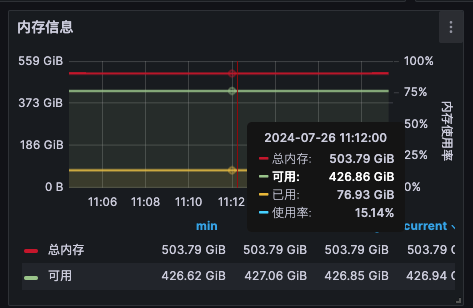
使用的 PromQL 为:
- 总内存,
node_memory_MemTotal_bytes{instance=~\"$node\"} - 已用,
node_memory_MemTotal_bytes{instance=~\"$node\"} - node_memory_MemAvailable_bytes{instance=~\"$node\"}
从数值上看,free 与 Grafana 数据基本一致。
因为 Grafana 使用的 Node Exporter 采集的 node_memory_Mem 这些指标来自主机的 /proc/meminfo 与 free -h 的数据同源。
2.2 top 使用的是 metrics-server 采集的指标
top 查看节点资源使用情况
| |
模拟 top 命令向 metrics-server 请求数据:
| |
这里的内存使用量约 130 Gi,130 / 503 = 25.8% 与 kubectl top node 基本一致。
2.3 metrics-server 的数据来自 Kubelet
从 metrics-server 的源码可以看到,其在请求 Kubelet 的数据。
| |
模拟 metrics-server 向 Kubelet 请求数据
| |
符合预期,请求 metrics-server 与 Kubelet API 提供的监控数据相同。
2.4 node_memory_working_set_bytes 指标有什么不同
- top 使用的是
node_memory_working_set_bytes,是 Kubelet 提供的指标
包括当前正在使用的内存,活跃的缓存,不包括可以被立即回收的缓存、缓冲区,主要是非活跃的文件缓存,其数据来源于 /sys/fs/cgroup。
- Grafana 使用的是
node_memory_MemTotal_bytes-node_memory_MemAvailable_bytes,是 Node Exporter 提供的指标
包括当前正在使用的内存,但不包括缓存,其数据来源于 /proc/meminfo。
前面可以看到 top 看到的内存使用量大约为 130 Gi,而 Grafana 看到的内存使用量大约是 77 Gi,相差 53 Gi 内存存储的就是一些不能立即被回收的缓存。但由于这两种方式的数据源不同,无法对 53 Gi 进行更详细的分析。
2.5 Kubelet limit 使用的是 container_memory_working_set_bytes
对于 Pod 来说,通过 top 和 Grafana 看到的内存使用量可能是相同的,因为,大部分 Grafana 面板绘制 Pod 内存使用量用的是 container_memory_working_set_bytes,这与 top 的计算方式是一致的。
这里需要重点关注的是 Kubelet 会以哪个指标驱逐 Pod? 答案是,container_memory_working_set_bytes 。
container_memory_working_set_bytes 更能代表容器的真实内存使用量。
下面这张图体现的是 container_memory_working_set_bytes (大约 18GiB) 与 container_memory_usage_bytes (大约 33GiB) 的区别。
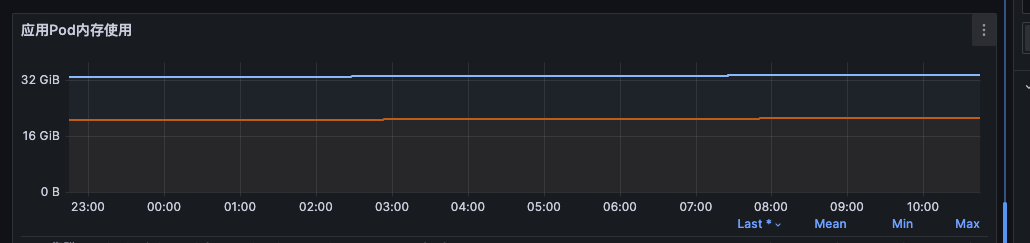
3. 总结
本文采集数据的主机内核版本为 5.4.0-48-generic,主要内容如下:
- 因为 Kubelet 预留资源,top node 资源使用率可能超过 100%,使用
--show-capacity可以看到总的资源使用情况 - 常用的节点资源使用率 (
node_memory_MemTotal_bytes-node_memory_MemAvailable_bytes)/node_memory_MemTotal_bytes,因为忽略了活跃的缓存资源,所以使用率会比 top node 看到的低一些。在上面例子中,Grafana 展示的是 15% 使用率,top node 展示的是 28%。 - Kubelet 对 Pod 驱逐使用的是
container_memory_working_set_bytes,与 top pod 看到的内存使用量相同
