Token 是一个与数据紧密相关的单位,可以用来度量训练模型所需的语料量,还可以用来度量推理时的输入和输出长度。
1. token 是什么
Token 可以是一个完整的单词、子词,甚至是一个字符。在语言模型中,文本被拆分为若干个 token,模型逐一处理这些 token 来生成预测或生成新文本。
下面是一些经验,可以帮助理解 token 的长度:
1 token ~= 5-6 chars in English
100 tokens ~= 90 words in English 或 10 sentences in English
可以通过 https://platform.openai.com/tokenizer 来查看 OpenAI 的 Tokenizer 表现,下面这个例子中,可以看到 token 与人理解的词并没有一一对应的关系。
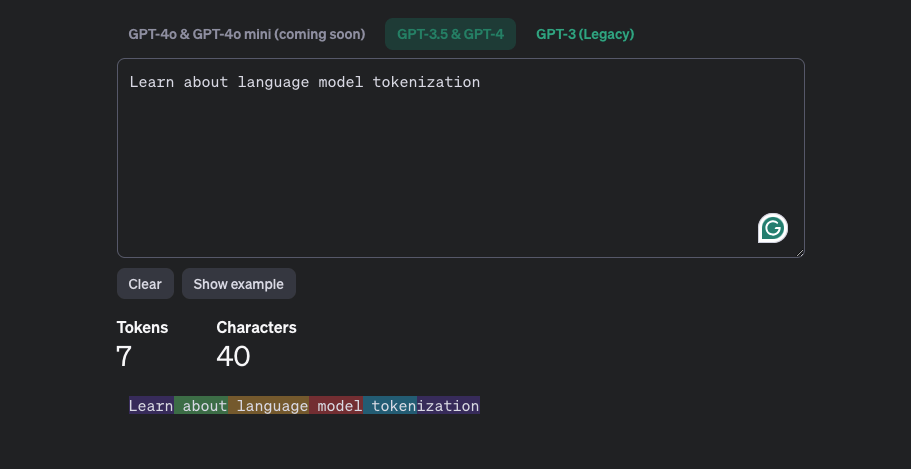
2. token 的 embedding
在上面的例子中,切换底部的 [Token IDs],可以看到文本对应的 token 的 embedding ids.
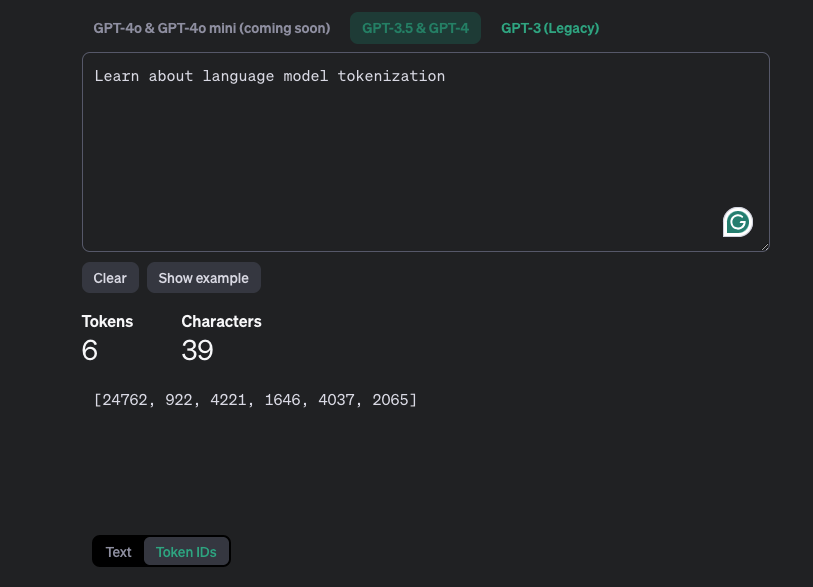
文本是给人看的,Token IDs 是给模型处理使用的。文本经过 Tokenizer 后,会变成一个或者多个 token,然后经过 embedding,转换为 Token IDs。而词表就存储着,每个 token 对应的 embedding id。
3. 词表是怎么生成的
词表通常在模型训练之前生成,在整个训练过程中,词表不会发生变化。
SentencePiece 是一个用于分词和词表生成的工具,支持多种分词算法,如 BPE、WordPiece 和 unigram。它被广泛应用于大模型的词表和分词器的构建中,例如 LLaMa、BLOOM、ChatGLM 和 Baichuan 等。
使用 SentencePiece 可以从语料中生成一个完整的词表,也可以用来扩充现有的词表。
比如,训练 LLaMa 时,使用的中文资料很少。在对模型针对中文语料进行微调之前,就需要先进行词表扩充,能够有效地提高模型的表现。
4. token 与数据大小的关系
下面是一个典型模型与预训练数据规模的对照表:
| 模型 | 参数规模 (B) | 预训练数据规模(tokens) |
|---|---|---|
| CodeGen | 16 | 577 B |
| LLaMA | 65 | 1.4 T |
| GPT-3 | 175 | 300 B |
其中 ,B 表示 Billion 十亿,T 表示 Trillion 表示万亿。
直接使用 tokens 作为数据规模有时不够直观,下面是 tokens 与文件大小的对照表:
| 文本类型 | 平均每 Token 字节数 | 1GB 文本数据的 Token 数量 |
|---|---|---|
| 英文 | 6 字节 | ( \frac{1 \times 2^{30}}{6} ≈ 0.167 B ) |
| 中文 | 3 字节 | ( \frac{1 \times 2^{30}}{3} ≈ 0.556 B ) |
| 文本类型 | 平均每 Token 字节数 | 1B Token 的文件大小 |
|---|---|---|
| 英文 | 6 字节 | ( 1B \times 6 ) 字节 ≈ 5.6 GB |
| 中文 | 3 字节 | ( 1B \times 3 ) 字节 ≈ 2.8 GB |
