1. 什么是 Ray
2016 年,UC Berkeley 的 RISELab 发布了一个新的分布式计算框架 Ray。
2017 年,发布 Ray 相关论文之后,受到业内的广泛关注,国内主要是蚂蚁集团采用并贡献了 Ray。
2020 年,Ray 发布了 1.0 版本,引入 Placement Group 特性,增加了用户自定义任务编排的灵活性,为后续的 Ray AI Libraries 和 vLLM 等项目提供了基础支持。
2021 年,Ray 发布了 1.5 版本,发布 Ray Data Alpha,弥补了 Ray 在 AI 数据处理和离线推理领域的空白,后续在 AI 数据处理方面得到广泛应用。
2022 年,Ray 发布了 2.0 版本,引入 Ray AIR(Ray AI Runtime)概念,聚焦 AI 生态,使用户能够基于此快速构建 AI 基建。
2023 年,Ray 发布了 2.9 版本,引入 Streaming Generator,原生支持流式推理能力,更好地适配大模型场景。大模型推理引擎 vLLM 基于 Ray Core 及 Ray Serve 构建分布式推理能力,进一步丰富了 Ray 的 AI 生态。
2024 年,Ray 发布了 Ray 2.32 版本,引入 Ray DAG,更好地支持 AI 场景下异构设备间的通信,持续推动 Ray 在分布式计算尤其是 AI 领域的应用和发展。
目前 Ray 最新的版本是 2.42.0。
2. Ray 的架构
2.1 架构图
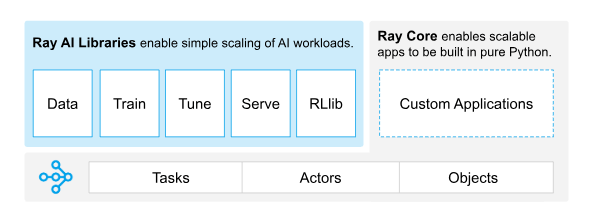
如上图,Ray 是由 Ray Core 和 Ray AI Libraries 两部分组成的。
2.2 Ray Core
Ray Core 是 Ray 的核心组件,提供了任务调度、状态管理和数据传输等能力。
其核心有三个部分:
Tasks 是 Ray 中并行计算的基本单元。Tasks 会被分发到不同的节点上执行,执行完毕后会将结果返回给调用方。
Actors 是 Ray 中带有状态的计算单元,用来维护任务之间的中间状态,适合需要长期运行或者有状态的计算。
Objects 是 Ray 中数据单元,用来在不同节点之间传递数据,保存中间结果,简化任务之间的数据传递。
2.3 Ray AI Libraries
基于 Ray Core 提供的在分布式场景下,对计算、状态和数据的管理能力,Ray AI Libraries 提供了一系列 AI 相关的库,通过这些库可以更方便的对接各种分布式计算场景。
可扩展的、与框架无关的数据加载和转换,涵盖训练、调优和预测。
用于分布式训练
可扩展的超参数调优,以优化模型性能
可扩展的强化学习工作负载
可扩展和可编程的服务,用于部署用于在线推理的模型,并可选择微批处理来提高性能。
3. 组建 Ray Cluster
组件 Ray Cluster 时,需要选择一台节点作为 Head Node 控制节点,其他节点作为 Worker Node 工作节点。
3.1 安装 Ray
1
| pip install ray==2.42.0
|
需要注意,保持 Head Node 和 Worker Node 的 Python、Ray 版本一致。
3.2 启动 Head Node
1
| ray start --head --port=6379
|
启动之后会输出 Local node IP。此时可以查看 ray 的状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| ray status
Node status
---------------------------------------------------------------
Active:
1 node_6059a3f888076423cb58ef7138d24e40b4e8c114784adcfaef92a407
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Usage:
0.0/32.0 CPU
0.0/4.0 GPU
0B/141.39GiB memory
0B/64.59GiB object_store_memory
Demands:
(no resource demands)
|
3.3 启动 Worker Node
设置 Head Node 的 IP
1
| export RAY_HEAD_IP=x.x.x.x
|
检测网络连通性
1
| nc -zv ${RAY_HEAD_IP} 6379
|
启动 Worker Node
1
| ray start --address=${RAY_HEAD_IP}:6379
|
3.4 在任意节点查看 Ray Cluster 状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| ray status
Node status
---------------------------------------------------------------
Active:
1 node_99586ba71470c3b36fca67056ccd507cc760f39ef1bdd747a28afd2d
1 node_6059a3f888076423cb58ef7138d24e40b4e8c114784adcfaef92a407
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Usage:
0.0/64.0 CPU
0.0/8.0 GPU
0B/298.09GiB memory
0B/131.74GiB object_store_memory
Demands:
(no resource demands)
|
此时可以看到 Ray Cluster 已经叠加了两个节点计算和存储资源,也包括 GPU 卡。
4. 测试 Ray Cluster
将以下代码保存为 ray_test.py。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| import ray
import itertools
ray.init(address="auto")
@ray.remote
def map_task(data_chunk):
"""模拟计算:对数据块中的元素平方"""
return [x * x for x in data_chunk]
@ray.remote
def reduce_task(results):
"""模拟 Reduce 任务:对所有结果求和"""
# 展开所有列表并求和
return sum(itertools.chain(*results))
# 模拟数据分块
data = list(range(1000))
chunk_size = 200
data_chunks = [data[i:i + chunk_size] for i in range(0, len(data), chunk_size)]
# 提交 Map 任务
map_results = [map_task.remote(chunk) for chunk in data_chunks]
# 解析 map 结果
map_values = ray.get(map_results)
# 提交 Reduce 任务
final_result = reduce_task.remote(map_values)
print("Final distributed computation result:", ray.get(final_result))
|
1
2
3
| 2025-02-09 11:39:15,281 INFO worker.py:1567 -- Connecting to existing Ray cluster at address: x.x.x.x:6379...
2025-02-09 11:39:15,288 INFO worker.py:1752 -- Connected to Ray cluster.
Final distributed computation result: 332833500
|
5. vLLM 多机推理
vLLM 官方文档有一个 Docker 的示例, https://docs.vllm.ai/en/latest/serving/distributed_serving.html 。
Ray 官方文档也有一个 vLLM 的示例, https://docs.ray.io/en/latest/serve/tutorials/vllm-example.html 。
Kubernetes 官方文档也有一个 vLLM 的示例 https://github.com/kubernetes-sigs/lws/tree/main/docs/examples/vllm 。
上面文档描述的都是基于 Ray 的多卡多机示例。这里直接在主机节点上进行测试,以便于后续针对不同运行时环境进行适配调整。
Ray Cluster 启动之后,只需要认为当前主机拥有全部 GPU 资源一样,启动 vLLM 服务即可。常见的多卡推理有两种方式,一种是 Tensor Parallel,一种是 Pipeline Parallel。
多机推理场景下,保障节点之间的高效通信至关重要,可以通过设置 NCCL_SOCKET_IFNAME 环境变量来指定卡间通信的网络接口。
1
2
| export NCCL_SOCKET_IFNAME=eth0
export NCCL_DEBUG=TRACE
|
有些卡可能需要设置
1
| export GLOO_SOCKET_IFNAME=eth0
|
1
2
3
4
5
6
7
8
| python3 -m vllm.entrypoints.openai.api_server \
--tensor-parallel-size 2 \
--model /data/ops/Qwen2.5-0.5B \
--served-model-name Qwen2.5-0.5B \
--trust-remote-code \
--dtype=half \
--host 0.0.0.0 \
--port 30000
|
在启动日志中,可以 vLLM 发现了 Ray Cluster,这里也可以使用 --pipeline-parallel-size 2 对模型进行切分。
1
2
3
4
5
6
7
8
9
| curl http://127.0.0.1:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen2.5-0.5B",
"messages": [
{"role": "user", "content": "介绍一下 Ray 计算引擎"}
],
"max_tokens": 1024
}'
|
6. 总结
本篇主要是介绍了 Ray 的基本概念和架构,以及如何搭建 Ray Cluster,最后通过一个简单的任务和 vLLM 示例来展示 Ray 的多机推理大模型使用。
Ray 的组网与之前的 MPI 通信原语及 Python 编程使用 有些类似,可能分布式场景下的计算和通信模式基本一致。
