1. 定义
LLM 推理过程中存在着两个截然不同的阶段,PD 分离就
- 计算密集型的 Prefill 阶段,
LLM 处理所有用户的 input,计算出对应的 KV Cache
- 显存密集型的 Decode 阶段,
顺序的产生一个个的 token,每次访存只计算一个 token
2. 指标
2.1 prefill 性能评估指标
TTFT(Time To First Token),表示生成第 1 个 token 所用的时间
P90 TTFT SLO = 0.4s,意味着我们对该系统的要求是:90%的 request 的 TTFT 值都必须<=0.4
2.2 decode 性能评估指标
TPOT(Time Per Output Token),产出每一个 response token 所用的时间
P90 TPOT SLO = 0.04s,意味着我们对该系统的要求是,在 90% 的 request 的 TPOT 值都必须<=0.04s
3. PD 分离带来的优势
在 long context 背景下,prefill 和 decode 阶段对计算和显存的需求非常不平衡。
- 充分利用设备资源
prefill 采用高算力的 GPU,decode 采用低算力大显存的 GPU
- 分开优化,能同时提升 TTFT 和 TPOT 指标
prefill 阶段应该限制 Batch Size 大小,decode 阶段应该增大 Batch Size 大小
4. batching 策略
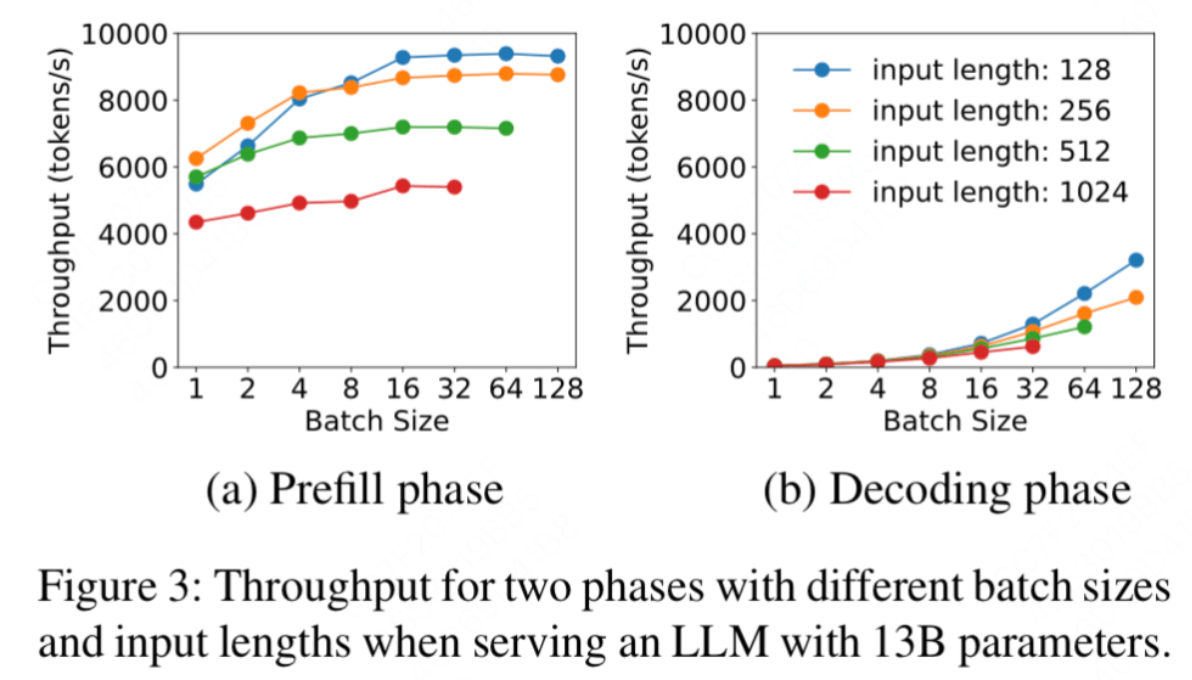
- prefill 阶段
因为 prefill 阶段是计算密集型,随着 batch size 的增加,算力受限,吞吐量的增长趋势趋于平缓。
- decode 阶段
因为 decode 阶段是带宽、内存密集,随着 batch size 的增加,吞吐量的增长趋势越来越显著。
