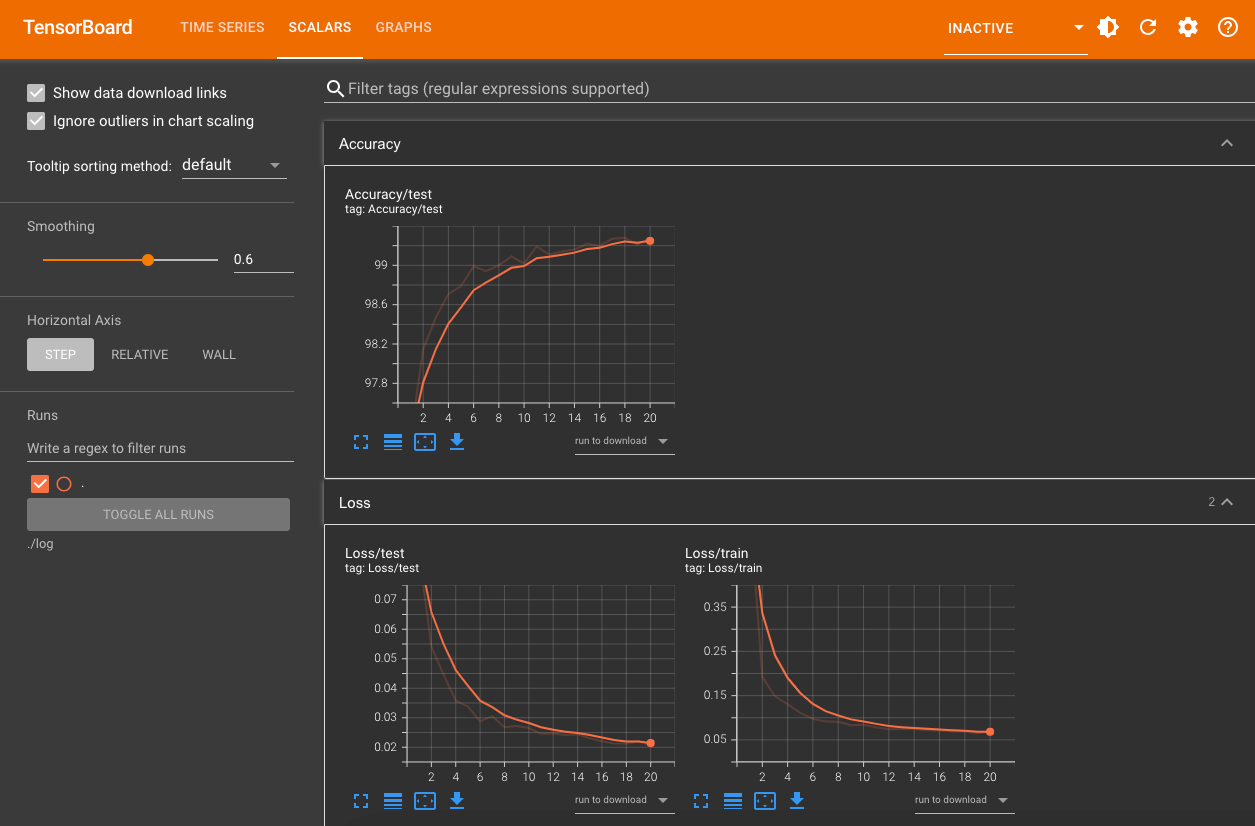
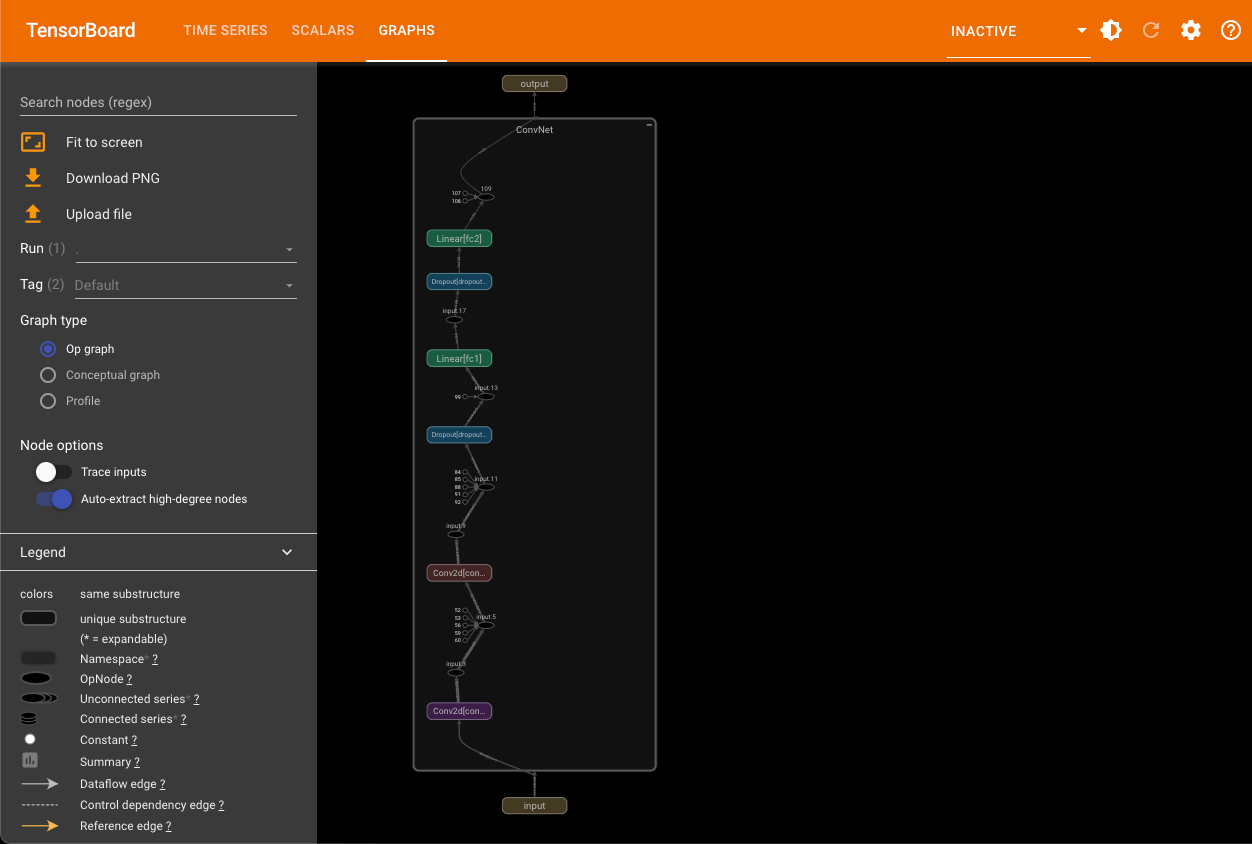
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
| import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.tensorboard import SummaryWriter
# 定义 TensorBoard 的写入器
writer = SummaryWriter("./log")
# 定义超参数
BATCH_SIZE = 512
EPOCHS = 20
LEARNING_RATE = 1e-3
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 数据加载和预处理,在 data 目录下载 MNIST 数据集
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(
"data",
train=True,
download=True,
transform=transforms.Compose(
[
transforms.RandomRotation(10), # 随机旋转,提高模型的泛化能力
transforms.RandomAffine(
0, shear=10, scale=(0.8, 1.2)
), # 仿射变换,提高模型的泛化能力
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
]
),
),
batch_size=BATCH_SIZE,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(
"data",
train=False,
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
),
),
batch_size=BATCH_SIZE,
shuffle=False,
)
# 定义模型的结构,这里是一个简单的卷积神经网络
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
self.dropout1 = nn.Dropout(0.25)
self.fc1 = nn.Linear(64 * 5 * 5, 128)
self.dropout2 = nn.Dropout(0.5)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = x.view(-1, 64 * 5 * 5)
x = F.relu(self.fc1(x))
x = self.dropout2(x)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
# 初始化模型和优化器
model = ConvNet().to(DEVICE)
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
scheduler = torch.optim.lr_scheduler.StepLR(
optimizer, step_size=5, gamma=0.5
) # 学习率衰减
# 添加模型结构到 TensorBoard
example_input = torch.randn(1, 1, 28, 28).to(DEVICE) # 创建一个示例输入
writer.add_graph(model, example_input) # 添加模型图
# 训练函数
def train(model, device, train_loader, optimizer, epoch):
model.train()
running_loss = 0.0 # 用于记录训练过程中累计的损失
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if (batch_idx + 1) % 30 == 0:
print(
f"Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} "
f"({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}"
)
# 将训练的平均损失写入 TensorBoard
writer.add_scalar("Loss/train", running_loss / len(train_loader), epoch)
# 测试函数
def test(model, device, test_loader, epoch):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction="sum").item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100.0 * correct / len(test_loader.dataset)
print(
f"\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)\n"
)
# 将测试的损失和准确率写入 TensorBoard
writer.add_scalar("Loss/test", test_loss, epoch)
writer.add_scalar("Accuracy/test", accuracy, epoch)
# 训练和测试循环
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch)
test(model, DEVICE, test_loader, epoch)
scheduler.step() # 更新学习率
# 保存模型
torch.save(model.state_dict(), "mnist_cnn.pth")
print("Model saved to mnist_cnn.pth")
# 关闭 TensorBoard 写入器
writer.close()
|