1. 数据处理架构
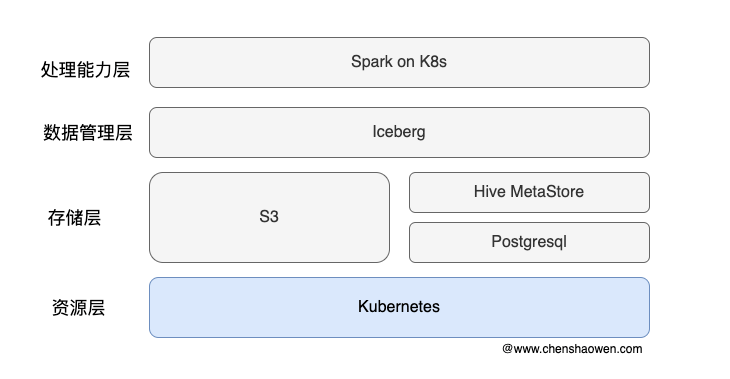
主要分为四层:
- 处理能力层,Spark on Kubernetes 提供流式的数据处理能力
- 数据管理层,Iceberg 提供 ACID、table 等数据集访问操作能力
- 存储层,Hive MetaStore 管理 Iceberg 表元数据,Postgresql 作为 Hive MetaStore 存储后端,S3 作为数据存储后端
- 资源层,Kubernetes 管理集群的计算、存储和网络资源,对上层提供统一的资源管理能力
1.1 Spark
Apache Spark 是一个开源集群运算框架,最初是由加州大学柏克莱分校 AMPLab 所开发。相对于 Hadoop 的 MapReduce 会在执行完工作后将中介资料存放到磁盘中,Spark 使用了内存运算技术,能在资料尚未写入硬盘时即在内存分析运算。
可以完成的任务包括:
- 批处理,提取、转换、加载、处理等
- 流处理,实时分析、事件处理
- SQL 查询,与 Hive、Iceberg 等数据源集成,提供强大的查询优化功能
- 机器学习,Spark 中的 MLlib 支持常见的机器学习算法,如回归、分类、聚类等
- 图计算,Spark 中的 GraphX 支持常见的图计算算法,如 PageRank 算法
Spark on Kubernetes 项目是一个在 Kubernetes 上运行 Apache Spark 应用程序的解决方案,提供了更加云原生的运行方式。
1.2 Iceberg
Iceberg 是一种表格式(tableformat),我们可以把它定义成一种数据组织格式。
Iceberg 是由 Netflix 开发并开源的、用于庞大分析数据集的开放表格式。Iceberg 在 Presto 和 Spark 中添加了使用高性能格式的表(Hudi 也支持 Presto 和 Spark 集成),该格式的工作方式类似于 SQL 表。
与底层的存储格式(比如 ORC、Parquet 之类的列式存储格式)最大的区别是,它并不定义数据存储方式,而是定义了数据、元数据的组织方式,向上提供统一的表的语义。
常见的使用方式是,在 Hive Metastore 建立一个 iceberg 格式的表。用 fink 或者 spark 写入 iceberg,然后再通过其他方式来读取这个表,比如 spark、flink、presto 等。本篇主要也是采用的这种技术路线。
1.3 Hive Metastore
Hive Metastore 是 Apache Hive 的核心组件之一,它主要用作元数据管理服务,为 Hive、Spark、Presto、Trino 等大数据处理工具提供了一个统一的元数据存储和访问层。
简单来说,Hive Metastore 负责管理和存储表的结构、数据库信息以及存储位置等元数据,方便分布式计算框架快速访问和处理大规模数据。
2. 部署 Hive Metastore
2.1 部署 PG
参考 https://github.com/shaowenchen/demo/tree/master/spark-3.5-iceberg 目录中的 postgres15.yaml 文件部署。
需要注意的是,示例中 PGSQL 存储使用的是本地主机 hostPath 存储。如果是生产环境,需要更换为更可靠的存储服务。
2.2 PG 数据库初始化
- 设置环境变量
| |
- 创建数据库
| |
2.3 部署 Hive Metastore
参考 https://github.com/shaowenchen/demo/tree/master/spark-3.5-iceberg 目录中的 hive-metastore.yaml 文件部署。
需要替换一下 S3 相关的存储桶配置,BUCKET、ACCESS_KEY、SECRET_KEY、ACCESS_KEY、SECRET_KEY 等。
Hive Metastore 使用 PGSQL 作为数据库后端,在部署的配置文件中有写 PGSQL 的信息。如果采用外部数据库,需要更新部署文件中的相关配置。
3. 部署 Spark Operator
3.1 Spark Operator 简介
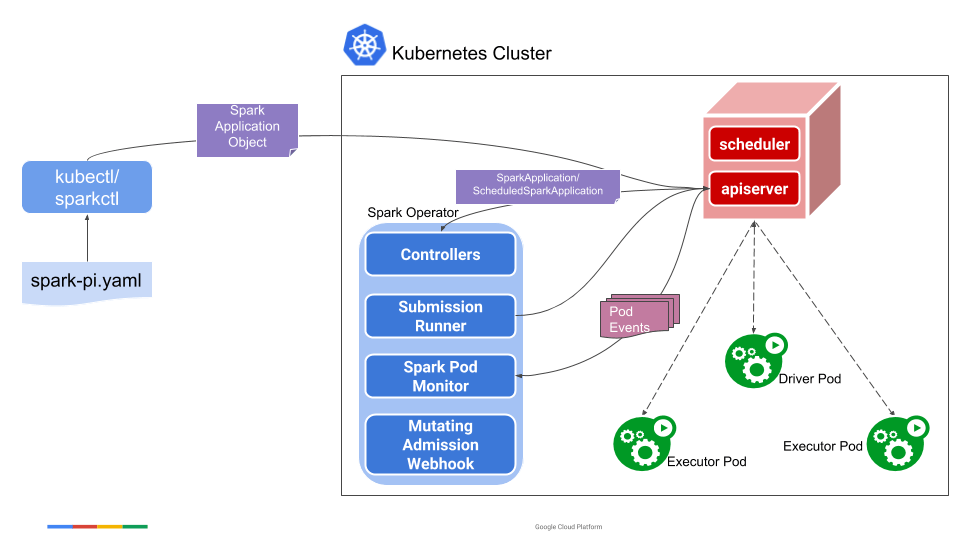
上图是 Spark Operator 的架构,展示了各个组件的关系。其工作流程如下:
- spark-submit 提交 Spark 作业到 Kubernetes 集群(可以通过 sparkapplications 对象来提交)
- Kubernetes 集群创建 Driver Pod
- Driver 启动若干 Executor Pods
- Executor 执行具体的 Task 任务
- 执行完成后,Driver 清理 Executor
3.2 安装 Spark Operator
- 添加 repo
| |
- 安装 spark-operator
| |
spark-operator 仅会处理 jobNamespaces 中指定的命名空间的 Spark 作业。
- 卸载 spark-operator
| |
- 查看负载
| |
- 查看 CRD
| |
sparkapplications.sparkoperator.k8s.io 定义的是 Spark 作业,scheduledsparkapplications.sparkoperator.k8s.io 定义的是定时执行的 Spark 作业。
4. 使用 Standalone Spark 和 Iceberg 处理数据
Standalone 模式下的 Spark 会在本地启动完整的依赖。
4.1 部署一个 standalone 的 Spark 实例
参考 https://github.com/shaowenchen/demo/tree/master/spark-3.5-iceberg 目录中的 spark-iceberg.yaml 文件部署。
4.2 进入 spark Pod 交互操作
| |
一共有三种可用的 spark 交互终端:
- spark-shell
- spark-sql
- spark-python
4.3 创建 Iceberg 表
执行 spark-sql 命令进入 spark-sql (default)> 终端
- 创建命名空间
| |
- 创建表
| |
上面命令创建的表会被保存到默认配置文件设置的 spark-warehouse 中,如果想要指定存储位置,可以使用 LOCATION 关键字指定。
| |
4.4 使用 spark-python 处理
退出 spark-shell 终端,将下面的代码保存到 Pod 中,使 python spark-example.py 执行。
| |
这个处理流程分为三部分:
- 数据加载,将外部原生 JSON 数据,也可以直接读取 Iceberg 表的数据。
- 数据处理,利用 Spark 的计算能力,对数据进行处理。
- 数据输出,将处理后的数据输出到外部存储 S3 中,提供给业务方使用。
此时,在对象存储中可以看到,Iceberg 表的数据
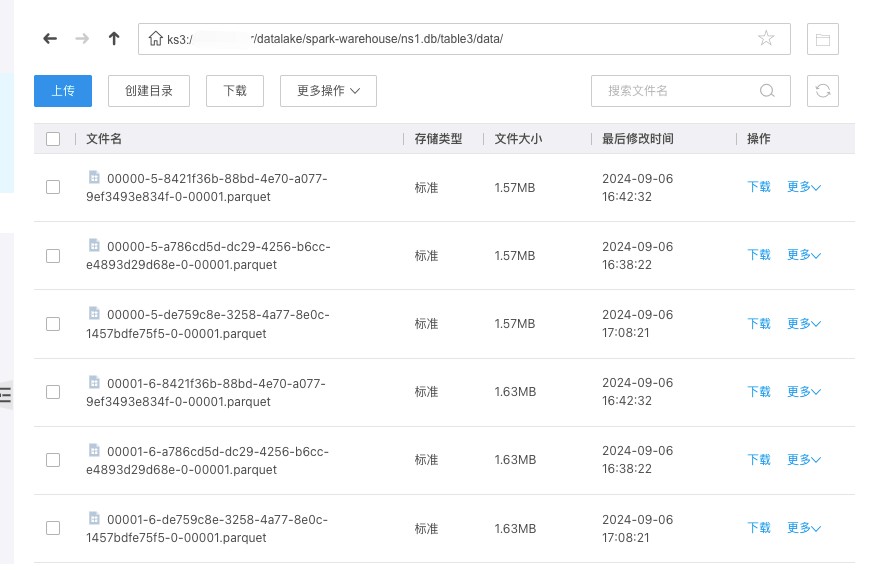
Iceberg 表的元数据
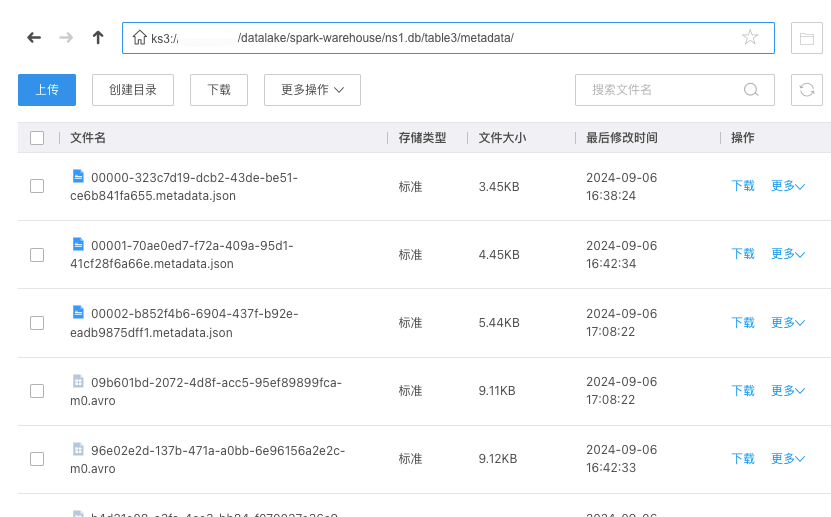
处理后导出的数据
5. 使用 Spark 在集群处理数据
5.1 使用 yaml 提交 Spark 作业
- 给 Driver 设置权限
| |
| |
- 提交 Spark 作业
| |
这里使用的是 Spark 官方镜像,内置有 examples 示例。
- 跟踪运行状态
| |
当 Completed 时,Spark 作业已完成;同时,executor pod 已经被清理掉,只留下 driver pod。
- 查看运行结果
| |
Driver 从 Executor 获取执行结果,然后输出到本地。
- 清理
| |
5.2 spark-submit 相关参数
| |
- 基本用法
spark-submit [选项] <应用程序 JAR 文件 | Python 文件 | R 文件> [应用程序参数]
spark-submit --kill [提交 ID] --master [spark://...]
spark-submit --status [提交 ID] --master [spark://...]
spark-submit run-example [选项] 示例类名 [示例参数]
- 选项(Options)
–master MASTER_URL:Spark 集群的主节点 URL(如 spark://host:port、mesos://host:port、yarn、k8s://https://host:port 或本地模式 local[*]),默认为 local[*](即使用本地所有 CPU 内核运行)。
–deploy-mode DEPLOY_MODE:指定驱动程序的部署模式,“client” 表示在本地运行驱动程序,“cluster” 表示在集群中运行驱动程序(默认为 client 模式)。
–class CLASS_NAME:你的应用程序的主类(针对 Java / Scala 应用程序)。
–name NAME:应用程序的名称。
–jars JARS:逗号分隔的 JAR 文件列表,包含在驱动程序和执行程序的类路径中。
–packages:逗号分隔的 Maven 坐标列表,指定要包含在驱动程序和执行程序类路径中的 JAR 包。首先会在本地 Maven 仓库中搜索,然后是 Maven Central 以及通过 --repositories 指定的其他远程仓库。
–exclude-packages:逗号分隔的 groupId:artifactId 列表,用于排除指定的依赖包,避免与 --packages 提供的依赖发生冲突。
–repositories:逗号分隔的远程仓库列表,用于搜索 --packages 指定的 Maven 坐标。
–py-files PY_FILES:逗号分隔的 .zip、.egg 或 .py 文件列表,这些文件会被放在 Python 应用的 PYTHONPATH 中。
–files FILES:逗号分隔的文件列表,文件会被放置在每个执行器的工作目录中,可通过 SparkFiles.get(fileName) 访问这些文件。
–archives ARCHIVES:逗号分隔的压缩文件列表,这些压缩文件会被解压到每个执行器的工作目录中。
–conf, -c PROP=VALUE:设置任意 Spark 配置属性。
–properties-file FILE:指定一个文件路径,从该文件中加载额外的配置属性。如果未指定,Spark 将默认查找 conf/spark-defaults.conf 文件。
–driver-memory MEM:指定驱动程序的内存大小(如 1000M,2G),默认为 1024M。
–driver-java-options:向驱动程序传递额外的 Java 选项。
–driver-library-path:为驱动程序传递额外的库路径。
–driver-class-path:为驱动程序传递额外的类路径。注意,使用 --jars 添加的 JAR 文件会自动包含在类路径中。
–executor-memory MEM:指定每个执行器的内存大小(如 1000M,2G),默认为 1G。
–proxy-user NAME:指定要提交应用时模拟的用户。此选项与 --principal 和 --keytab 不兼容。
–help, -h:显示帮助信息并退出。
–verbose, -v:打印额外的调试信息。
–version:打印当前 Spark 的版本信息。
- Spark Connect(仅限 Spark Connect 模式)
–remote CONNECT_URL:指定连接 Spark Connect 服务的 URL,例如 sc://host:port。此选项无法与 --master 和 --deploy-mode 一起设置。该选项为实验性质,可能会在小版本更新中发生变化。
- 集群部署模式(Cluster Deploy Mode Only)
–driver-cores NUM:指定驱动程序使用的核心数(仅在集群模式下使用,默认为 1)。
- Spark Standalone 或 Mesos(仅限集群模式)
–supervise:如果指定此选项,驱动程序在失败时会自动重启。
- Spark Standalone、Mesos 或 K8S(仅限集群模式)
–kill SUBMISSION_ID:指定后,杀死具有该 ID 的驱动程序。
–status SUBMISSION_ID:指定后,获取具有该 ID 的驱动程序状态。
- Spark Standalone 和 Mesos(仅限 Standalone 和 Mesos 模式)
–total-executor-cores NUM:为所有执行器指定使用的总核心数。
- Spark Standalone、YARN 和 Kubernetes(仅限 Standalone、YARN 和 K8S 模式)
–executor-cores NUM:每个执行器使用的核心数(在 YARN 和 Kubernetes 模式下默认为 1,在 Standalone 模式下默认为工作节点上所有可用的核心)。
- Spark on YARN 和 Kubernetes(仅限 YARN 和 K8S 模式)
–num-executors NUM:启动的执行器数量(默认为 2)。如果启用了动态资源分配,初始的执行器数量至少为指定的值。
–principal PRINCIPAL:指定用于登录到 KDC 的主体。
–keytab KEYTAB:指定主体对应的 keytab 文件的完整路径。
- Spark on YARN(仅限 YARN 模式)
–queue QUEUE_NAME:指定 YARN 的队列名称,默认为 “default”。
5.3 使用 spark-submit 提交 Spark 作业
- 进入 Pod 终端
| |
- 提交 Spark 作业
在上面的步骤中,已经给 default ServiceAccount 设置了足够权限,这里直接指定 master 地址即可。
| |
其中的 –conf 包含大量配置参数,详见 https://spark.apache.org/docs/latest/running-on-kubernetes.html
执行时,会输出与 Kubernetes 交互的信息,主要是 Pod 的状态
- 查看相关的 Pod
| |
与上面一样,driver 执行完成之后会保留下来,executor 会被删除掉。
- 查看相关日志
| |
6. 使用 Spark 和 Iceberg 在集群处理数据
由于在生产环境下,Spark 处理的脚本有时会发生调整,为了便于更新和管理脚本,在 Spark 处理数据的脚本需要通过 PVC 挂载到 Driver 、Executor 中。
参考 https://github.com/shaowenchen/demo/blob/master/spark-3.5-iceberg/sparkapp.yaml
7. 使用 Argo Webhook 对外提供 Spark 处理 API
- 创建 Sensor
https://github.com/shaowenchen/demo/blob/master/spark-3.5-iceberg/argo-sensor.yaml
- 创建一个 EventSource
| |
- 检测 Sensor Pod 状态
| |
- 查看 Webhook 的服务端口
| |
- 调用 API 接口触发任务
| |
通过 script 可以指定启动脚本,path 可以用来隔离 pvc 中的目录。
8. 总结
本篇记录了部署基于 Spark 、Iceberg、Hive Metastore 的数据处理软件栈的流程。主要内容如下:
- 介绍了 Spark 、Iceberg、Hive Metastore 的基本概念
- 部署 Hive Metastore、Spark Operator
- 测试使用 Standalone 模式运行 Spark 作业
- 测试使用 spark-submit、yaml 方式运行 Spark 作业
- 通过 Argo Webhook 对外提供 Spark 数据处理 API
