1. 分布式训练面临的问题
需要多少算力、需要多少时间、需要多少带宽、需要多少 CPU、需要多少内存,如果没有足够的积累,很难估算准确。导致的结果就是,超额申请、超额分配,造成极大的资源浪费。
需要去沉淀和提供解决方案。
算法同学不太了解 Kubernetes 基础设施,运维同学不太了解训练过程,想要当好 AI Infra Engineer 不是件容易的事。
训练场景下的故障率非常高,如何快速、准确地定位并解决故障,是我们需要思考的问题。
- 单个节点发生故障,全部节点停止训练,需要人值守才能及时拉起作业继续训练
训练作业类似 Kubernetes 中的 StatefulSet。分布式训练中,由于数据、模型、流水线、张量等并行技术的存在,每个节点在训练过程中并不是完全对等的。
从发生故障到恢复训练,有很多技术点可以落地到工具、产品上。
同时,如果是非工作时间段发生故障,我们无法及时响应,模型迭代延期、AI 加速卡闲置都是巨大损失。能不能自动发现故障、自动恢复训练,也是值得研究的问题。
2. 什么是 DLRover
DLRover 就试图解决上诉问题的一个方案。下面是 https://github.com/intelligent-machine-learning/dlrover 项目的架构图。
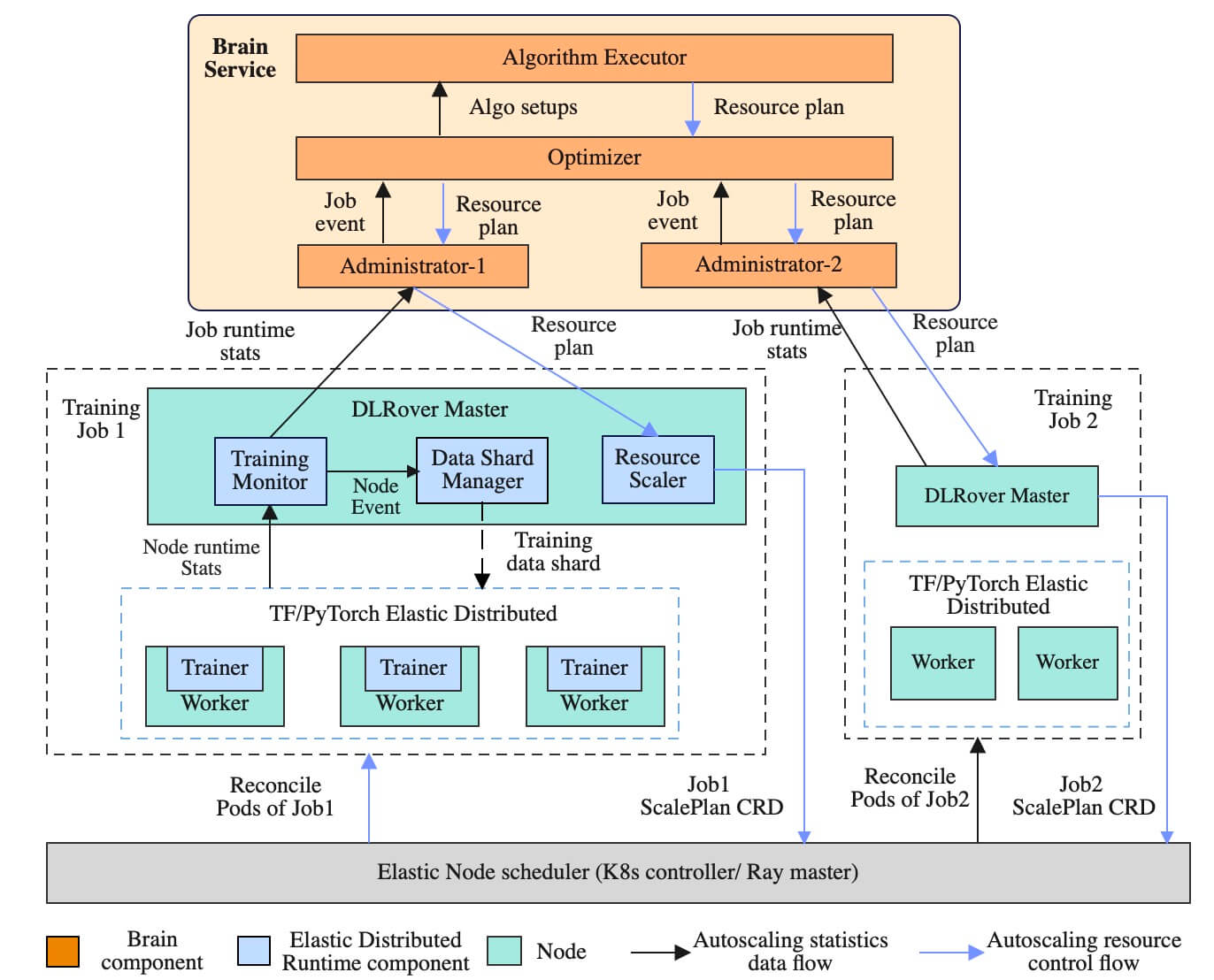
管理平面的组件:
- Brain Service,负责资源弹性优化。基于实时采集的训练速度和各个节点负载来自动优化作业的资源配置,还有一个事件采集服务 k8smonitor
- Elastic Controller,是 Kubernetes 对象 ElasticJob、ScalePlan 的控制器
CRD 对象:
- ElasticJob 用来描述弹性训练作业
- ScalePlan 用于在 Brain、DLRover Master、Elastic Controller 之间传递信息,以做出优化调整。一般不需要主动创建,DLRover 会自动管理
训练作业相关的组件:
- DLRover Job Master,负责弹性调度、容错自愈。每个训练作业拥有一个 master 节点, master 节点负责训练速度采集、节点负载收集、训练样本管理和弹性调度。
- Elastic Agent 不用单独部署,是需要使用
dlrover-run 命令托管训练作业,负责与训练框架协调来支持训练的容错和弹性。每个节点上都有一个 Elastic Agent, Agent 从 master 上获取作业当前运行的节点信息,通知训练框架更新分布式训练状态。 Agent 还负责从 master 获取训练样本信息来供训练框架迭代模型,从而使训练样本分片支持 worker 的弹性。
下面这张图是其容错的架构设计:
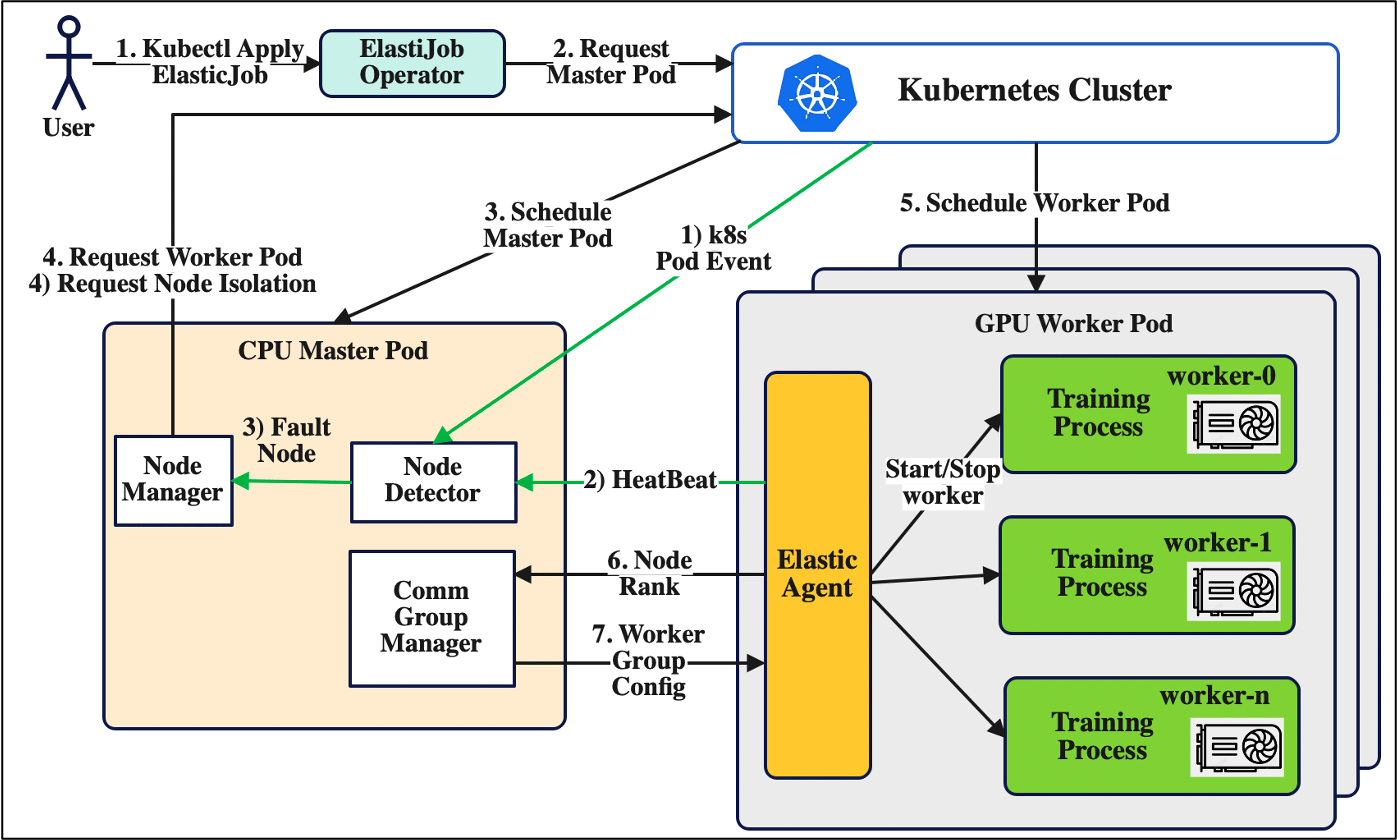
DLRover Job Master 负责探测、处理故障,dlrover-run 作为 Agent 上报状态信息。
3. dlrover-run 命令及参数
1
| pip install dlrover[torch] -U -i https://mirrors.aliyun.com/pypi/simple
|
dlrover-run 只是对 dlrover.trainer.torch.main 的封装
1
2
3
4
5
6
7
8
9
10
| cat /usr/local/bin/dlrover-run
#!/usr/local/bin/python
# -*- coding: utf-8 -*-
import re
import sys
from dlrover.trainer.torch.main import main
if __name__ == '__main__':
sys.argv[0] = re.sub(r'(-script\.pyw|\.exe)?$', '', sys.argv[0])
sys.exit(main())
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| dlrover-run --help
用法: dlrover-run [-h] [--nnodes NNODES] [--nproc-per-node NPROC_PER_NODE] [--rdzv-backend RDZV_BACKEND] [--rdzv-endpoint RDZV_ENDPOINT]
[--rdzv-id RDZV_ID] [--rdzv-conf RDZV_CONF] [--standalone] [--max-restarts MAX_RESTARTS]
[--monitor-interval MONITOR_INTERVAL] [--start-method {spawn,fork,forkserver}] [--role ROLE] [-m] [--no-python]
[--run-path] [--log-dir LOG_DIR] [-r REDIRECTS] [-t TEE] [--node-rank NODE_RANK] [--master-addr MASTER_ADDR]
[--master-port MASTER_PORT] [--local-addr LOCAL_ADDR] [--network-check] [--node-unit NODE_UNIT] [--auto_config]
[--auto_tunning] [--exclude-straggler] [--save_at_breakpoint] [--accelerator {nvidia.com/gpu,ascend-npu}]
training_script ...
Torch Distributed Elastic Training Launcher
位置参数:
training_script 启动并行执行的训练程序/脚本的完整路径,后跟训练脚本的所有参数。
training_script_args 训练脚本的参数
可选参数:
-h,--help 显示帮助信息并退出
--nnodes NNODES 节点数量或节点范围,格式为 <minimum_nodes>:<maximum_nodes>。
--nproc-per-node NPROC_PER_NODE,--nproc_per_node NPROC_PER_NODE
每个节点的工作进程数量;支持的值:[auto,cpu,gpu,int]。
--rdzv-backend RDZV_BACKEND,--rdzv_backend RDZV_BACKEND
Rendezvous 后端。
--rdzv-endpoint RDZV_ENDPOINT,--rdzv_endpoint RDZV_ENDPOINT
Rendezvous 后端的端点;通常格式为 <host>:<port>。
--rdzv-id RDZV_ID,--rdzv_id RDZV_ID
用户定义的组 ID。
--rdzv-conf RDZV_CONF,--rdzv_conf RDZV_CONF
附加的 rendezvous 配置(<key1>=<value1>,<key2>=<value2>,...)。
--standalone 启动一个本地独立的 rendezvous 后端,使用 C10d TCP 存储在端口 29400 上。用于启动单节点、多工作进程作业时非常有用。如果指定,则 --rdzv-backend、--rdzv-endpoint、--rdzv-id 会被自动分配;任何显式设置的值将被忽略。
--max-restarts MAX_RESTARTS,--max_restarts MAX_RESTARTS
最大的工作进程组重启次数,超出此次数将失败。
--monitor-interval MONITOR_INTERVAL,--monitor_interval MONITOR_INTERVAL
监控工作进程状态的时间间隔,单位为秒。
--start-method {spawn,fork,forkserver},--start_method {spawn,fork,forkserver}
创建工作进程时使用的多进程启动方法。
--role ROLE 工作进程的用户定义角色。
-m,--module 将每个进程更改为将启动脚本解释为 Python 模块,行为与 'python -m' 相同。
--no-python,--no_python
跳过在训练脚本前添加 'python' - 直接执行脚本。如果脚本不是 Python 脚本时非常有用。
--run-path,--run_path
使用 runpy.run_path 在相同解释器中运行训练脚本。脚本必须提供为绝对路径(例如 /abs/path/script.py)。优先于 --no-python。
--log-dir LOG_DIR,--log_dir LOG_DIR
用于日志文件的基础目录(例如 /var/log/torch/elastic)。相同的目录会被多个运行重用(会创建一个以 rdzv_id 为前缀的唯一作业级子目录)。
-r REDIRECTS,--redirects REDIRECTS
将标准流重定向到日志目录中的日志文件(例如 [-r 3] 重定向所有工作进程的 stdout+stderr,[ -r 0:1,1:2] 重定向本地 rank 0 的 stdout 和本地 rank 1 的 stderr)。
-t TEE,--tee TEE 将标准流分流到日志文件和控制台(参见 --redirects 格式)。
--node-rank NODE_RANK,--node_rank NODE_RANK
多节点分布式训练中节点的排名。
--master-addr MASTER_ADDR,--master_addr MASTER_ADDR
主节点(rank 0)的地址,仅用于静态 rendezvous。它应该是 rank 0 的 IP 地址或主机名。对于单节点多进程训练,--master-addr 可以简单地是 127.0.0.1;IPv6 应该是 `[0:0:0:0:0:0:0:1]` 的模式。
--master-port MASTER_PORT,--master_port MASTER_PORT
主节点(rank 0)上用于分布式训练期间通信的端口。仅用于静态 rendezvous。
--local-addr LOCAL_ADDR,--local_addr LOCAL_ADDR
本地节点的地址。如果指定,将使用给定的地址进行连接。否则,将查找本地节点地址。否则,默认为本地计算机的 FQDN。
--network-check,--network_check
是否在启动训练过程前检查网络。
--node_unit NODE_UNIT,--node-unit NODE_UNIT
要调度的节点数量单位。调度的节点数量应为 node_unit 的倍数。
--auto_config,--auto-config
是否自动配置 nnodes 和 nproc_per_nodes。
--auto_tunning,--auto-tunning
是否自动调优并行配置。
--exclude-straggler,--exclude_straggler
布尔值,如果节点是滞后节点且参数为 True,则该节点将退出。该参数仅在 network-check 为 True 时有效。
--save_at_breakpoint,--save-at-breakpoint
布尔值。如果为 True,主进程中的代理将在训练过程失败时将检查点保存到存储中。
--accelerator {nvidia.com/gpu,ascend-npu}
机器的加速器芯片类型。
|
4. 使用 DLRover 快速托管训练
1
| nerdctl -n k8s.io run --rm -it --gpus all registry.cn-beijing.aliyuncs.com/intell-ai/dlrover:pytorch-example bash
|
1
2
3
4
5
6
7
8
| export RANK=0
export LOCAL_RANK=0
export WORLD_SIZE=1
export MASTER_ADDR="localhost"
export MASTER_PORT=1234
python3 examples/pytorch/mnist/cnn_train.py --num_epochs 1 \
--training_data /data/mnist_png/training/ \
--validation_data /data/mnist_png/testing/
|
我发现 --no-cuda 参数无效,只能通过控制 GPU 挂载来指定仅使用 CPU 训练。
不用设置环境变量直接运行即可,DLRover 帮我们省去了设置环境变量的步骤。
1
2
3
4
5
| dlrover-run --network-check --nnodes=1 \
--nproc_per_node=1 --max_restarts=3 \
examples/pytorch/mnist/cnn_train.py --num_epochs 1\
--training_data /data/mnist_png/training/ \
--validation_data /data/mnist_png/testing/
|
由于使用的是单个容器进行训练,需要将 --nnodes 参数设置为 1,否则 DLRover 会一直等待新节点加入,max_restarts 设置为 3 允许失败之后重试 3 次。
5. 集群安装 DLRover 相关组件
这里安装的是 DLRover 最新的 Release 版本 v0.3.7 ,是今年 5.13 发布的。
1
2
3
| wget https://github.com/intelligent-machine-learning/dlrover/archive/refs/tags/v0.3.7.tar.gz
tar xvf v0.3.7.tar.gz
cd dlrover-0.3.7
|
- 安装 ElasticJob Controller Manager
1
| kubectl -n dlrover apply -k dlrover/go/operator/config/manifests/bases
|
需要注意的是默认的权限设置在 dlrover 空间下,如果想在其他空间使用,则需要创建与之对应的 default-role.yaml。
1
2
3
4
| kubectl -n dlrover get pod
NAME READY STATUS RESTARTS AGE
dlrover-controller-manager-6d676545d7-nrc4g 2/2 Running 0 73s
|
1
2
3
4
| kubectl get crd |grep elastic
elasticjobs.elastic.iml.github.io 2024-08-15T07:27:29Z
scaleplans.elastic.iml.github.io 2024-08-15T07:27:29Z
|
如果仅使用训练 worker 自动恢复的功能,那么不用安装 Brain 等组件。因为 Brain 依赖 MySQL,仅为测试,下面部署 MySQL 的方式并不可靠。
1
| kubectl -n dlrover apply -f dlrover/go/brain/manifests/k8s
|
查看 MySQL Pod 名
1
2
3
| kubectl -n dlrover get pod |grep mysql
mysql-85dd8c7fdb-kdxtz 1/1 Running 0 7m41s
|
执行命令,创建数据库以及初始化表
1
2
3
| kubectl exec -it mysql-85dd8c7fdb-kdxtz --namespace dlrover -- bash
cd dlrover
mysql -uroot -proot < dlrover-tables.sql
|
1
| kubectl -n dlrover rollout restart deployment dlrover-brain dlrover-kube-monitor
|
1
2
3
4
5
6
7
| kubectl -n dlrover get pod
NAME READY STATUS RESTARTS AGE
dlrover-brain-689c4b77d4-bqcz9 1/1 Running 0 3m55s
dlrover-controller-manager-6b6f9dcd88-2h2fs 2/2 Running 0 6m19s
dlrover-kube-monitor-69ff5f99f4-gwqws 1/1 Running 0 3m55s
mysql-799f94cbfd-864th 1/1 Running 0 4m17s
|
6. ElasticJob 创建训练作业
6.1 ElasticJob 对象定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| type ElasticJobSpec struct {
// DistributionStrategy 指定作业的分发策略。
// 目前,策略支持 parameter-server 和 ring-allreduce。
DistributionStrategy string `json:"distributionStrategy,omitempty"`
// ResourceLimits 指定作业的最大资源。例如,
// {"cpu": "100", "memory": "10240Mi"} 表示最大 CPU 核数为 100,所有 Pod 的最大内存为 10Gi。
ResourceLimits map[string]string `json:"resourceLimits,omitempty"`
// OptimizeMode 指定优化作业资源的模式。
// 目前支持 "manual"(手动)、"single-job"(单作业)、"cluster"(集群)。
OptimizeMode string `json:"optimizeMode,omitempty"`
// BrainService 指定 Brain 的地址,以优化作业资源。Brain 可以单独部署,配置在 ElasticJobSpec 中。
// 仅在 optimizeMode 为 cluster 时使用。
BrainService string `json:"brainService,omitempty"`
// EnableElasticScheduling 启动 Pod 的弹性调度。
EnableElasticScheduling bool `json:"enableElasticScheduling,omitempty"`
// EnableDynamicSharding 启动数据集的动态分片。
EnableDynamicSharding bool `json:"enableDynamicSharding,omitempty"`
// 一个从 ReplicaType(类型)到 ReplicaSpec(值)的映射。指定训练集群的配置。
// 例如,
// {
// "PS": ReplicaSpec,
// "Worker": ReplicaSpec,
// }
ReplicaSpecs map[commonv1.ReplicaType]*ReplicaSpec `json:"replicaSpecs"`
// Envs 指定作业 Pod 的环境变量。
Envs map[string]*corev1.EnvVar `json:"envs,omitempty"`
}
|
其中的 ReplicaSpec 定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| type ReplicaSpec struct {
commonv1.ReplicaSpec `json:",inline"`
// RestartCount 是重新启动失败副本的次数。
RestartCount int `json:"restartCount,omitempty"`
// AutoScale 是一个标志,用于自动调整副本数量和每个副本的资源。
AutoScale bool `json:"autoScale,omitempty"`
// RestartTimeout 是等待挂起副本的时间。
RestartTimeout int `json:"restartTimeout,omitempty"`
// Priority 支持 high/low/0.5。0.5 表示一半的工作节点具有高优先级,
// 另一半工作节点具有低优先级。默认值为 low。
Priority string `json:"priority,omitempty"`
}
|
下面对其中的一些关键字段进行说明。
6.2 DistributionStrategy 策略
有两种 DistributionStrategy 策略:
适用于使用 TensorFlow 的 parameter_server 作业,https://www.tensorflow.org/tutorials/distribute/parameter_server_training 。
适用于 Horovod 的 ring-allreduce 和 PyTorch 的 DistributedDataParallel 作业。
从这里可以看出,如果训练使用的是 PyTorch 就选 AllreduceStrategy,使用的是 TensorFlow 就选 ParameterServerStrategy。
PyTorch DistributedDataParallel 的 Allreduce 策略下,预训练过程中会保持 Global Batch Size 固定,也就不需要增删节点,不涉及弹性训练,主要使用的是 Job Master 的容错自愈能力。
TensorFlow parameter_server 的 ParameterServerStrategy 策略下,节点数可以调整,依赖 Brain 服务进行弹性训练。
6.3 optimizeMode 模式
有三种 optimizeMode 模式:
调试模式,修改正在运行的作业时,作业不会重启,用来探索更佳的作业参数配置。
测试、快速验证的场景,不依赖额外的组件。使用 master 的内存存储历史的统计数据,如果主节点发生故障,历史统计数据会丢失。
正式环境的训练,Bran 服务会将作业的历史统计数据持久化到数据库中,进行集群级别的优化。即使主节点发生故障时,DLRover 可以重启主节点继续训练。
上面这段描述来自 DLRover 的设计文档。在测试时,发现 single-job\cluster 模式在 AllreduceStrategy 下没有明显区别,cluster 模式在 Brain 不能用时也能正常运行。同时,AllreduceStrategy 下的 Job Master 发生故障时,整个作业就失败了。
6.4 训练作业测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| kubectl apply -f - <<EOF
apiVersion: elastic.iml.github.io/v1alpha1
kind: ElasticJob
metadata:
name: torch-mnist-single-job-testing-1
namespace: dlrover
labels:
some-label: some-value
spec:
distributionStrategy: AllreduceStrategy
optimizeMode: cluster
replicaSpecs:
worker:
replicas: 5
template:
spec:
restartPolicy: Always
containers:
- name: main
image: registry.cn-beijing.aliyuncs.com/intell-ai/dlrover:pytorch-example
imagePullPolicy: Always
command:
- /bin/bash
- -c
- "dlrover-run --network-check --nnodes=1:10 \
--nproc_per_node=1 --max_restarts=10 \
examples/pytorch/mnist/cnn_train.py --num_epochs 500 \
--training_data /data/mnist_png/training/ \
--validation_data /data/mnist_png/testing/"
resources:
limits:
cpu: 2
memory: 3Gi
tencent.com/vcuda-core: 100
requests:
cpu: 2
memory: 3Gi
tencent.com/vcuda-core: 100
EOF
|
一旦 ElasticJob 创建完成,DLRover 会马上开始创建 master 和 worker Pod,并不会判断是否有足够的资源,没有 gang-scheduler 的支持。根据社区沟通,DLRover 会结合 Volcano 的 gang-scheduler 支持此特性。
1
2
3
4
5
6
7
8
9
| kubectl -n dlrover get pod
NAME READY STATUS RESTARTS AGE
elasticjob-torch-mnist-single-job-testing-1-dlrover-master 1/1 Running 0 10s
torch-mnist-single-job-testing-1-edljob-worker-0 1/1 Running 0 5s
torch-mnist-single-job-testing-1-edljob-worker-1 1/1 Running 0 5s
torch-mnist-single-job-testing-1-edljob-worker-2 1/1 Running 0 5s
torch-mnist-single-job-testing-1-edljob-worker-3 1/1 Running 0 5s
torch-mnist-single-job-testing-1-edljob-worker-4 1/1 Running 0 5s
|
1
| kubectl -n dlrover delete pod torch-mnist-single-job-testing-1-edljob-worker-3
|
1
2
3
4
5
6
7
8
9
| kubectl -n dlrover get pod
NAME READY STATUS RESTARTS AGE
elasticjob-torch-mnist-single-job-testing-1-dlrover-master 1/1 Running 0 6m18s
torch-mnist-single-job-testing-1-edljob-worker-0 1/1 Running 0 6m13s
torch-mnist-single-job-testing-1-edljob-worker-1 1/1 Running 0 6m13s
torch-mnist-single-job-testing-1-edljob-worker-2 1/1 Running 0 6m13s
torch-mnist-single-job-testing-1-edljob-worker-4 1/1 Running 0 6m12s
torch-mnist-single-job-testing-1-edljob-worker-5 1/1 Running 0 3m12s
|
DLRover 会自动拉起一个新的 worker 作业,继续训练任务,这就是其故障自动恢复的能力。当然,如果是其他故障,比如掉卡、程序异常退出、IO 异常等故障,DLRover 也可以自动处理,不需要人工干预。
1
| kubectl -n dlrover delete elasticjob torch-mnist-single-job-testing-1
|
1
| kubectl -n dlrover delete scaleplans.elastic.iml.github.io torch-mnist-single-job-testing-1
|
6.5 弹性作业原理
Allreduce 现在只支持容错,不支持弹性扩容。我们的目标场景是 PyTorch 的分布式预训练大模型,对 Tensorflow 相关的弹性没有强烈需求。这里仅仅只是简单了解下其弹性原理。
DLRover Brain 会根据当前训练任务的监控,利用算法计算出资源优化需要调整的数据。训练作业的 Job Master 拿到新的资源优化结果后,会生成一个 ScalePlan CRD,通知 ElasticJob Controller 更改训练作业的节点规模。
我测试过社区提供的 deepctr-auto-scale 示例,chief 占用了大量内存资源,并没有观察到 worker 副本数的增加。
1
| deepctr-auto-scale-edljob-chief-0 1947m 185022Mi
|
1
2
3
4
5
6
7
8
| deepctr-auto-scale-edljob-chief-0 1/1 Running 0 4h42m
deepctr-auto-scale-edljob-evaluator-0 1/1 Running 0 4h42m
deepctr-auto-scale-edljob-ps-0 1/1 Running 0 4h42m
dlrover-brain-78b6484859-p67s5 1/1 Running 0 16h
dlrover-controller-manager-688c767cb7-8bzgl 2/2 Running 1 (7h43m ago) 15h
dlrover-kube-monitor-88548c89f-kjjjw 1/1 Running 1 (16h ago) 16h
elasticjob-deepctr-auto-scale-dlrover-master 1/1 Running 0 4h42m
mysql-574fb78ddb-8l79r 1/1 Running 0 16h
|
同时,这个作业依赖于 /nas 中的数据,文档中也没有给出配置说明,因此没有测试太多。
7. 一些问题
1
| kubectl -n dlrover delete pod elasticjob-torch-mnist-single-job-testing-1-dlrover-master
|
之后
1
| dlrover-controller-manager-6b6f9dcd88-2h2fs 1/2 CrashLoopBackOff 4 (35s ago) 58m
|
dlrover-controller-manager CrashLoopBackOff 的概率还挺高。等待一会儿,作业也会全部失败。
1
2
3
4
5
| torch-mnist-single-job-testing-1-edljob-worker-0 0/1 Error 0 112s
torch-mnist-single-job-testing-1-edljob-worker-1 0/1 Error 0 112s
torch-mnist-single-job-testing-1-edljob-worker-2 0/1 Error 0 112s
torch-mnist-single-job-testing-1-edljob-worker-3 0/1 Error 0 112s
torch-mnist-single-job-testing-1-edljob-worker-4 0/1 Error 0 112s
|
- ElasticJob 对象缺失非关键字段时,Worker 无法创建
不设置 spec.template.spec.restartPolicy 字段时,仅创建了 Job Master,而不会创建 Worker。在 ElasticJob Manager 和 Job Master Pod 的日志中看不到异常报错。
不设置作业 ElasticJob 的 labels 字段,也是这种情况。
在 Release 的版本中,镜像 Tag 还是 test、master,拉取策略是 Always。文档中的一些测试 Case 也没有太多版本控制,很容易触发兼容性问题。
还有就是 DLRover master 的 Dockerfile 中使用的 0.3.6 ,而 pytorch-example 中使用的是 0.3.4。
我看到 EnableElasticScheduling 字段很快就联想到了 autoScale 字段,但是发现只有这个字段的定义,代码仓库中没有相关的实现。
可能是开源的同学支持内部压力大,没太多时间打磨社区版这些细节,有些包名还没来得从 EasyDL 改为 DLRover。
8. 总结
本篇是测试 DLRover 托管训练作用的一些记录,主要内容如下:
- 在 Kubernetes 上进行训练,有其特定场景的问题需要解决,分布式训练任务形态类似 StatefulSet,节点(Pod) 之间不是完全对等
- DLRover 能解决分布式训练时的一些问题,包括资源的配置,弹性训练,故障的检测、定位、恢复。
- 在主机和 Kubernetes 基础设施上分别对 DLRover 进行了尝试
- 目前 DLRover 项目还有些不完善的地方,但也给了我们共同参与的机会,希望项目能够走得远一点
