1. Qwen 模型介绍
2023 年 4 月,阿里巴巴推出 Qwen 的测试版。
2023 年 12 月,阿里巴巴开源了 Qwen 的第一个版本。
2024 年 9 月,阿里巴巴发布了 Qwen2.5。
2025 年 1 月,阿里巴巴发布了 Qwen 2.5-Max。
Qwen 2.5 是 Qwen 大语言模型的目前最新系列。之所以说是系列,是因为在训练完一个预训练模型之后,为了最大化模型的价值,我们会针对业务场景和资源需求,对模型进行微调、蒸馏、裁剪、量化,得到不同的模型,以达到不同用途下性能和资源消耗的平衡。
除了基座模型,Qwen2.5 还发布有对数学、编程、指令微调的版本;参数规模从 0.5 B 到 72 B 不等;还有 Int4、Int8 的量化版本。
Qwen 系列大模型在各种榜单上都取得了很好的成绩,在我们的生产环境中,也有部分业务使用的就是基于 Qwen 进行微调的模型。
2. 准备环境
1
| wget "https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-$(uname)-$(uname -m).sh"
|
1
| bash Miniforge3-$(uname)-$(uname -m).sh
|
1
2
| echo "export PATH=$HOME/miniforge3/bin:$PATH" >> ~/.bashrc
source ~/.bashrc
|
1
| conda create -n qwen python=3.12
|
1
| git lfs clone https://huggingface.co/Qwen/Qwen2.5-0.5B
|
1
2
3
4
5
6
7
8
9
10
11
12
| tree Qwen2.5-0.5B
.
├── config.json
├── generation_config.json
├── LICENSE
├── merges.txt
├── model.safetensors
├── README.md
├── tokenizer_config.json
├── tokenizer.json
└── vocab.json
|
1
| conda install transformers pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
|
3. 查看模型结构
1
| export CUDA_VISIBLE_DEVICES=0
|
1
2
3
4
| from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("./Qwen2.5-0.5B")
print(model)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| Qwen2ForCausalLM(
# 这是一个 CausalLM 模型
(model): Qwen2Model(
(embed_tokens): Embedding(151936, 896)
# 表示输入的词嵌入层,输入的词表大小为 151936,输出的维度为 896
(layers): ModuleList(
# 一共有 24 层 decoder 层
(0-23): 24 x Qwen2DecoderLayer(
# 自注意力层
(self_attn): Qwen2Attention(
# QKV 矩阵的维度, 输出维度为 896
(q_proj): Linear(in_features=896, out_features=896, bias=True)
(k_proj): Linear(in_features=896, out_features=128, bias=True)
(v_proj): Linear(in_features=896, out_features=128, bias=True)
(o_proj): Linear(in_features=896, out_features=896, bias=False)
)
# 前馈网络层,这里由 MLP 构成,
(mlp): Qwen2MLP(
# 门控线性层
(gate_proj): Linear(in_features=896, out_features=4864, bias=False)
# 上游投影
(up_proj): Linear(in_features=896, out_features=4864, bias=False)
# 下游投影
(down_proj): Linear(in_features=4864, out_features=896, bias=False)
# 激活函数shi
(act_fn): SiLU()
)
# 多头注意力,输入特征维度为 896
(input_layernorm): Qwen2RMSNorm((896,), eps=1e-06)
# 对多头注意力输出特征进行归一化处理
(post_attention_layernorm): Qwen2RMSNorm((896,), eps=1e-06)
)
)
# 归一化处理,为下一层的输入做准备
(norm): Qwen2RMSNorm((896,), eps=1e-06)
# 位置编码,将位置信息加入到特征向量中
(rotary_emb): Qwen2RotaryEmbedding()
)
# 线性层,将特征向量映射到词表大小
(lm_head): Linear(in_features=896, out_features=151936, bias=False)
)
|
1
2
| num_params = sum(p.numel() for p in model.parameters())
print(f"模型参数总量: {num_params / 1e9:.5f} B")
|
1
2
3
4
| from transformers import AutoConfig
config = AutoConfig.from_pretrained("./Qwen2.5-0.5B")
print(config)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| Qwen2Config {
"_name_or_path": "./Qwen2.5-0.5B",
"architectures": [
"Qwen2ForCausalLM"
],
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151643,
"hidden_act": "silu",
"hidden_size": 896,
"initializer_range": 0.02,
"intermediate_size": 4864,
"max_position_embeddings": 32768,
"max_window_layers": 24,
"model_type": "qwen2",
"num_attention_heads": 14,
"num_hidden_layers": 24,
"num_key_value_heads": 2,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 1000000.0,
"sliding_window": null,
"tie_word_embeddings": true,
"torch_dtype": "bfloat16",
"transformers_version": "4.48.1",
"use_cache": true,
"use_mrope": false,
"use_sliding_window": false,
"vocab_size": 151936
}
|
其中,
max_position_embeddings 表示模型支持的最大序列长度为 32768。
num_attention_heads 表示多头注意力的头数,num_key_value_heads 表示表示用于 key 和 value 的独立部分数量, num_attention_heads / num_key_value_heads 就是每个 key-value 组中包含多少个注意力头。
torch_dtype 表示模型的数据类型,bfloat16 表示半精度浮点数
vocab_size 表示词表大小为 151936。
4. 哪些因素决定模型的参数量
这里有一个估算模型参数量的公式:
参数量 ≈ (隐藏层大小的平方 × 4 + 隐藏层大小 × 中间层大小) × 隐藏层层数 + 词汇表大小 × 隐藏层大小
下面是一些典型的模型结构参数:
| 模型名称 | 参数量 | 隐藏层维度 | 层数 | 注意力头数 |
|---|
| Qwen-0.5B | ~0.5B | 896 | 24 | 14 |
| Llama-7B | 7B | 4096 | 32 | 32 |
| Llama-13B | 13B | 5120 | 40 | 40 |
| Yi-34B | 34B | 7168 | 60 | 56 |
| Llama-65B | 65B | 8192 | 80 | 64 |
| DeepSeek-67B | 67B | 8192 | 80 | 64 |
5. 为什么需要 Embedding 层
有两个问题:
1,为什么要进行这样的变换
计算机能够有效处理的是数值型连续数据,而离散的词汇(如单词、字符、标记等)无法直接输入到神经网络中进行计算。
Embedding 层将离散的词汇(如单词、字符、标记等)转换为连续的、低维的向量表示的一层。
2,为什么是这样的变换
传统的独热编码(One-Hot Encoding)等方式,会导致向量维度极高且稀疏,存在计算量大、过拟合、表达能力差等问题。
在训练时,Embedding 层的向量表示可以捕捉到单词之间的语义相似性。
举个例子,[“狗”, “猫”, “鱼”],对应的索引分别是 [0, 1, 2],词表大小为 3。假设,隐藏层大小为 3,Embedding 层的输出是一个 3x3 的矩阵,每一行对应一个词的嵌入向量。
输入:[0, 1, 2],输出:
1
2
3
4
5
| [
[0.1, 0.3, 0.5], # 对应 "狗" 的嵌入向量
[0.2, 0.4, 0.6], # 对应 "猫" 的嵌入向量
[0.3, 0.5, 0.7] # 对应 "鱼" 的嵌入向量
]
|
这里也可以看到 Embedding 层大小 = 词表大小 × 隐藏层大小
在训练的过程中,Embedding 层的参数会随着模型的训练而不断调整,使得模型能够更好地捕捉到词汇之间的语义相似性。
6. 什么是 CausalLM 模型
CausalLM (Causal Language Model,因果语言模型)是一种自回归语言模型,生成文本时,只依赖于已经生成的文本,不依赖于未来的文本。
CaualLM 模型通常采用的是 Decoder-only 的 Transformer 架构,即只有解码器部分,没有编码器部分。
编码器提取输入序列的特征,得到一个固定长度的向量表示。编码器通常采用双向注意力机制,能够关注到整个序列的信息。
解码器会根据已经生成的输出元素以及上下文向量来预测下一个输出元素,直到达到预设的终止标记。解码器通常采用单向注意力机制,只能关注到已经生成的部分序列。
6.1 Encoder-Olny
Encoder-Only 模型只包含编码器,没有解码器,只能看到输入序列,不能利用已经生成的序列。
通常用于特征提取、文本分类等任务。
6.2 Encoder-Decoder
Encoder-Decoder 模型是既包含编码器,也包含解码器,能够看到输入序列和输出序列。
通常用于序列到序列的任务,如机器翻译、文本摘要等。
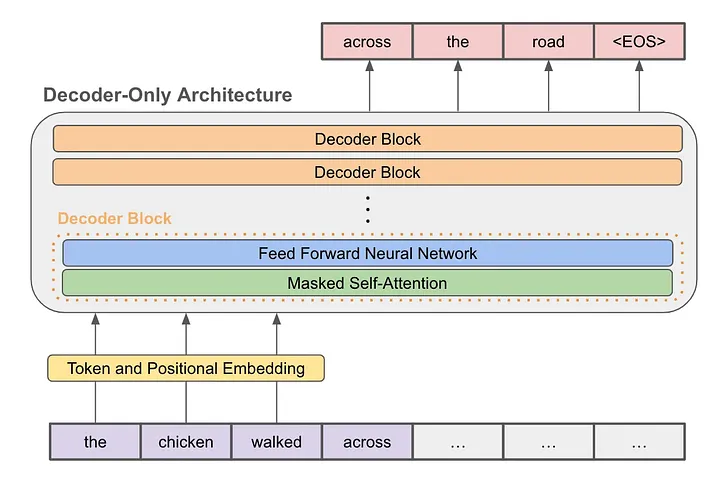
6.3 Decoder-Only
Decoder-Only 模型只包含解码器,没有编码器,只能看到已经生成的序列。
通常用于 GPT 等任务,如文本生成、对话生成等。掩码机制,保障了解码器只能看到已经生成的序列,而不能看到未来的序列。
下图是一个典型的 Decoder-Only 模型的结构:
7. 前馈网络层的作用
Qwen2MLP 作为 Transformer 架构里编码器或解码器模块中的前馈网络层,它的作用是在多头自注意力机制处理完序列信息之后,进一步对特征进行非线性变换和信息整合。
前馈网络层通常是由以下两个主要步骤组成:
- 线性变换,对输入进行加权处理
可以用公式 y=Wx+b 表示,其中 W 是权重矩阵,b 是偏置向量,x 是输入向量,y 是输出向量。
- 非线性激活函数,增加模型的表达能力
可以用公式 y=f(Wx+b) 表示,其中 f 是激活函数,用来控制神经元的激活程度。
常用激活函数有 ReLU、GELU、SiLU 等。
在训练过程中,前馈网络层需要不断地调整权重矩阵 W 和偏置向量 b,使得模型能够更好地拟合训练数据。
8. RMSNorm 归一化的作用
有两个问题:
- 为什么要进行归一化
通过归一化来去除输入的尺度差异,减少输入的变化范围,这有助于模型在训练过程中更容易收敛
- 为什么使用 RMSNorm
RMSNorm 是一种新型的归一化方法,它是一种基于均方根的归一化方法,与 BatchNorm、LayerNorm 等传统归一化方法相比,主要的优点是不用计算样本的均值,速度提升了 40%。
9. RoPE 旋转位置编码
纯粹的 Attention 模块是无法捕捉输入顺序的,即无法理解不同位置的 token 代表的意义不同。
RoPE 的核心思想是将位置编码与词向量通过旋转矩阵相乘,使得词向量不仅包含词汇的语义信息,还融入了位置信息,其具有以下优点:
- 相对位置感知:RoPE 能够自然地捕捉词汇之间的相对位置关系。
- 无需额外的计算:位置编码与词向量的结合在计算上是高效的。
- 适应不同长度的序列:RoPE 可以灵活处理不同长度的输入序列。
