本文内容整理自我在一次内部分享的部分内容。
1. 存储系统的核心要素
1.1 安全
对象存储桶的凭证、使用存储 PVC 时的授权、对访问来源的控制,这些都是安全需要关注的问题。
但这些又非常容易被忽视,出了问题就是大问题。
1.2 生命周期管理
存储系统是为业务使用数据服务的。
业务对数据的生命周期管理,直接影响着存储系统功能上的需求。
数据的产生-清洗-使用-流转-归档,这些流程的背后都需要存储系统及各种组件的支持。
1.3 性能
性能是衡量存储系统的重要指标。各种存储系统中,吞吐、延时、IOPS,这些都是我们需要关注的性能指标。
通过 dd、fio 等工具,我们可以评估各种存储系统的性能。然后,去调优,去修改参数、去提升带宽,以达到最佳性能。
1.4 存储成本
成本能最直接影响决策者的存储选择。
通常,性能越好,存储需要付出的成本越高,而实际需求需要我们自行评估,在性能与成本之间做出平衡决策。
对于很多公司来说,存储成本会占到整个 IT 成本的很大一部分。因此,对大规模使用的存储服务都非常敏感,决策时也会多一层非技术侧的考虑。
1.5 运维成本
由于基础设施的急剧变化,传统的存储系统不一定适合云原生的应用场景。这些存储在 Kubernetes 上使用和运维成本很高,有时,甚至部署这些存储系统也很困难。
适配云原生的存储系统,可能只需要执行一条 helm install 命令就可以完成部署,而且具有良好的可观测性,自愈的特性,这些不是每一个存储系统都具有的。
同时,日常繁琐的业务配置,也非常消耗运维同学的精力和时间,如何降低人力的成本是一个挑战。
2. 存储建设所处的阶段
我们总能找到很多的最佳实践,得到很多的参考建议,但直接按部就班的落地,会困难重重、甚至引发众怒。
这些最佳实践说得对,我们做得也很努力,就是得不到好的结果。因为,所处的阶段不同、人力投入不同、业务形态不同,很多总结最佳实践的人可能自己都忽略掉了这些因素。
成功的总结不是成功的全部,而是其自认为困难的部分。
对存储系统的阶段进行分析,能够准确识别当前最迫切需要关注的问题。
2.1 早期: 运维成本、性能
在项目的早期,从 0 到 1 ,我们并不会考虑太多,只要能快速实现就行,项目着急上线。
这个阶段主要是依赖人工进行运维和配置,运维同学的意见比决策者的意见更重要。
只要性能够好、方便配置,就能先落地试试,其他问题优先级比较低。
2.2 中期: 存储成本、生命周期管理
经过一段时间的试验,大家会对存储的一些特性有所了解,会有很多想要去优化和调整的地方。
而存储规模越来越大,存储成本越来越高,来自老板的压力也越来越大。同时,各种业务功能,跨产品、跨团队的存储、流转需求,也导致存储系统的复杂性升高,推高了维护成本。
此时,最大问题就是要根据数据的冷热分层,根据不同需求对性能的不同要求去降低存储成本。通过 Fluid 等组件对数据进行管理,以应对上层的业务需求。
2.3 后期: 安全,生命周期管理
开始关注数据安全时,存储的规模应该很大了,同时功能上的建设应该也很完善。
数据安全是绕不开的一个问题,其潜藏着巨大的风险。一次大的安全事故,就可能直接导致前面所有的努力白费,甚至相关人员直接离职。
怎样才能避免这些风险是后期迫切需要考虑的问题。
3. 存储系统的演进方向
3.1 面向对象存储的数据交付
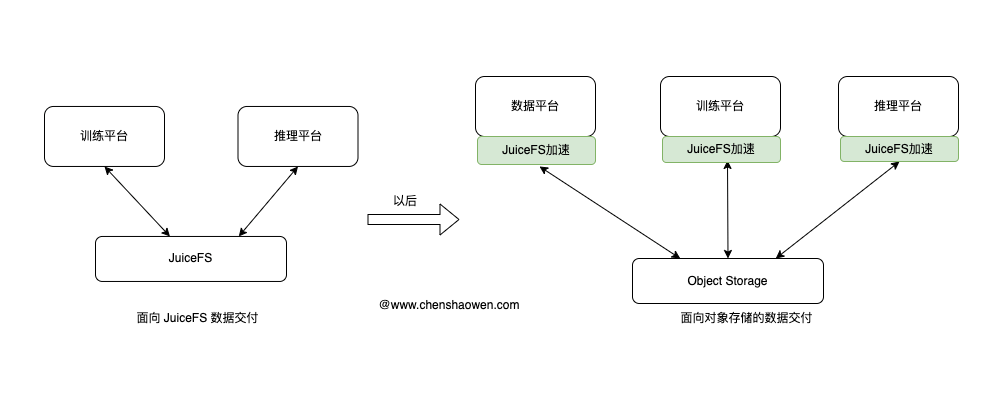
目前我们的工作方式是,训练和推理平台直接在 JuiceFS 中共享、拷贝数据。当前的问题是:
- JuiceFS 存储空间有限,虽然我们购买了 1P、500TB 的企业版存储,但还是不够用
- JuiceFS 成本比对象存储高
- JuiceFS 中的数据缺少生命周期管理
而面向对象存储的数据交付,强调的是在交付过程中,我们要对数据进行归档、封板。数据平台、训练平台、推理平台的数据交付,应该基于对象存储,而不是 JuiceFS。
演进之后能解决的问题
- 各平台按照自己的冷热数据管理 JuiceFS 缓存
- 有利于解耦平台
- 解除内网专线的依赖,阿里云直接访问金山云的 JuiceFS
- 各平台根据云厂使用缓存服务,金山云用 Juicefs、OSS 用 Jindo
3.2 面向集中存储的研发工作流
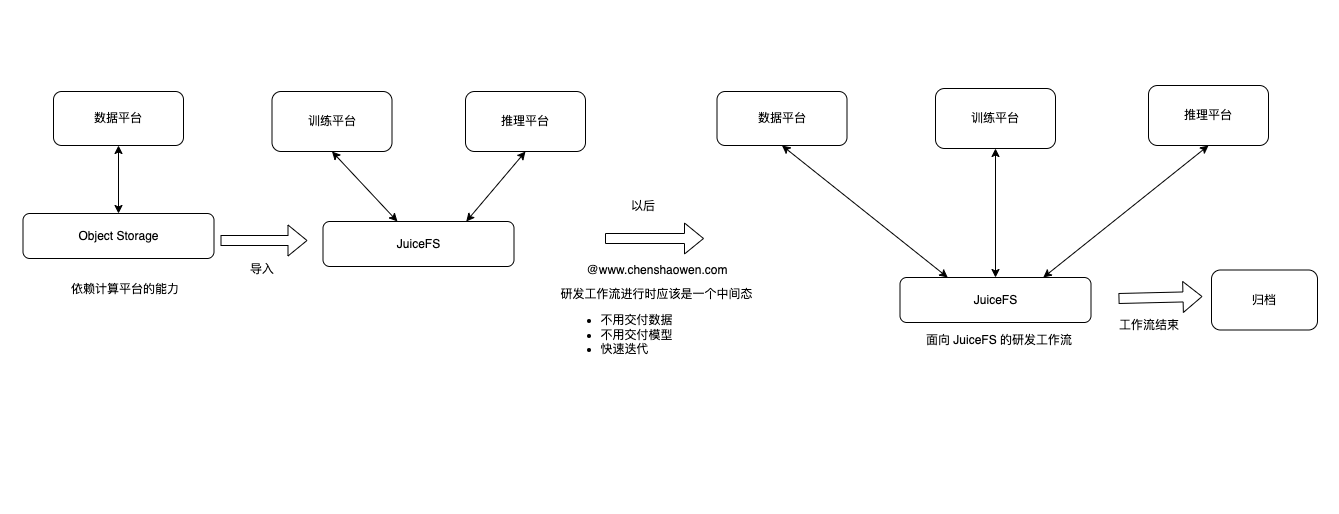
面向集中存储的研发工作流,强调的是处于中间态的数据,应该集中存储和流转。
研发工作流是一个中间态,具有以下特征:
- 不用交付数据
- 不用交付模型
- 快速迭代
面向 JuiceFS 的研发工作流优势:
- JuiceFS 的速度有绝对优势
- 流转效率更高,避免频繁导数据
