1. 让 Ops Copilot 成为 Ops Coilot
在 2023 年 09 月,我写过一版 Ops Copilot,也有文章发出 我在给 Ops 工具写 Copilot
。
实现的效果是这样的:
| |
此时,本地默认的浏览器就会被打开。
| |
但这样的功能对 Ops 项目来说,并没有什么意义,有很多开源项目也能提供这样的能力。
在交互对话的过程中,Ops Copilot 完全忽略了 Ops 提供的能力。这就是症结所在,我停顿了一段时间没有更新 Copilot 相关的功能。
Ops Copilot 最近一次的迭代需求来自工作岗位的生产需求,解决各种 AI 基础设施的异常问题。思路来自于,服务化的 AI Agent 和流水线化的 AI 任务。
下面一起看看这次迭代的若干关键点吧。
2. Ops Copilot 的设计
Ops Copilot 是借助于 LLM 整合 Ops 能力的一个 CLI 子命令。主要想解决以下问题:
- 如何选择合适的 Task 解决问题
- 如何提取执行相关 Task 的参数
下面是 Ops Copilot 的处理逻辑:
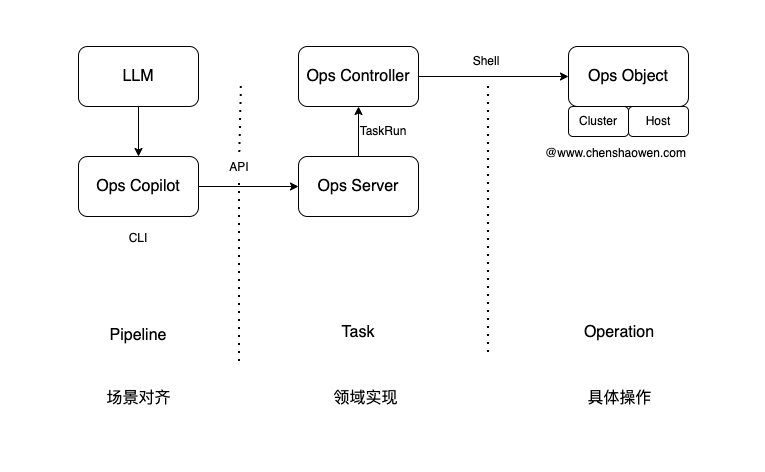
通过 Pipeline 的定义描述场景,借助 LLM 将文本输入转换为执行某一个 Pipeline,并提取相关参数。
Ops Copilot 会解析 Pipeline 并执行 Task 任务。Ops Copilot 通过 Ops Server 与 Ops Controller 交互,创建 TaskRun 任务等待 Ops Controller 执行完成,并获取结果。
Ops Server 是 2024 年初给 Ops 新增 UI 迭代时更新的组件,提供有鉴权能力,能够创建 Task 执行实例 TaskRun。
Ops Controller 会 Watch TaskRun 的创建,根据其中指定的 Cluster 或者 Host 对象,拿到相关的凭证连接 Ops Obsject 对象,执行相关操作。
而对 Cluster 和 Hosts 对象的操作,脚本执行、文件分发,正是 Ops 项目的核心设计。
按照这样的思路,Ops Copilot 才是真正基于 Ops 项目构建的子命令,融入到 Ops 项目中,如下图。
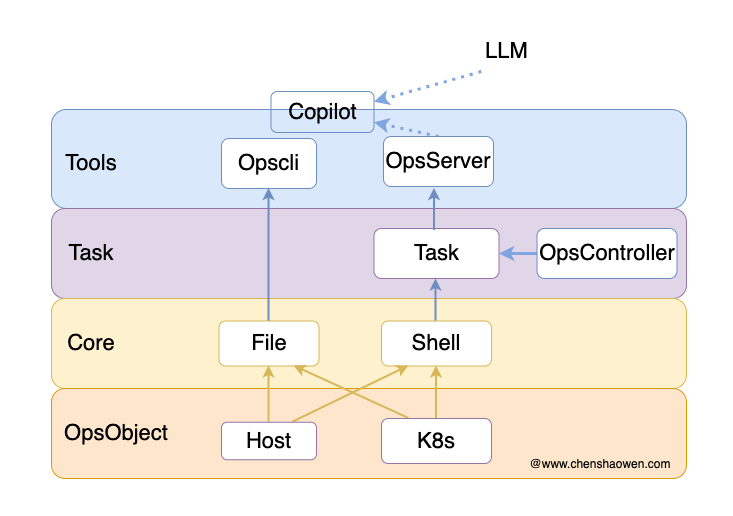
3. Ops Copilot 使用
3.1 参数说明
| |
copilot 会默认从环境变量获取 OPENAI_API_HOST、OPENAI_API_BASE、OPENAI_API_MODEL、OPENAI_API_KEY、OPS_SERVER, OPS_TOKEN,如果环境变量不存在,则使用默认值。
3.2 安装
如果之前已经安装,需要执行
opscli upgrade以升级到最新版本。
- 国内使用
| |
- 国外使用
| |
3.3 使用
- 设置环境变量
| |
- 运行 Copilot
| |
- 查看支持哪些操作
| |
这些流水线定义在 https://github.com/shaowenchen/ops/blob/main/pkg/copilot/pipelines.go 中。希望后面能有一种更好的扩展机制,比如从 Ops 部署的集群自动发现。
- 查询有哪些集群
| |
Ops Copilot 会定时从 Ops 部署的集群上拉取集群列表、主机列表的数据。
- 重启一个 Pod
| |
在集群上可以看到相关 Pod 的状态更新。
| |
一个流水线通常会包含若干 Task 任务。这些 Task 有两个来源:
- Ops Copilot 从 Ops 部署的集群定时获取到的 Task 任务,这部分在 Ops 的 Github 仓库下有很多
- 硬编码的 Task 任务,https://github.com/shaowenchen/ops/blob/main/pkg/copilot/tasks.go ,允许扩展和 Ops 无关的 Task 任务,比如 summary 使用 LLM 对输出进行总结、allow-whitelist 对操作员白名单进行控制等
4. 对齐是关键
4.1 场景意图的对齐
由于职业经历,我落地过 Gitlab CI,开发过 Github Action 插件,迭代过基于 Jenkins 的项目,从 0 到 1 分别开发过基于 Tekton 和 Argo Workflow 的项目。因此,在遇到需要设计执行逻辑时,我潜意识就选择了使用任务组装流水线的方式来执行 AI 任务。
下面是一个流水线定义:
| |
- Desc,让 LLM 知道这个 Pipeline 的作用是什么
- LLMTasks,包含 Pipeline 执行的具体逻辑
还有一些默认值或者配置,这些都是为了让 LLM 能够准确对输入进行匹配,又将 LLM 约束在我们定义的规则之内。
Desc 将每条流水线的用途准确提供给 LLM,LLM 根据输入的文本,选择执行哪条 Pipeline 来解决文本描述的问题,而这个 Pipeline 具体执行什么 Task 却是我们来解决的。
4.2 变量提取的对齐
提取变量是另外一个关键点,请看下面的例子。
| |
有两种方式可以有效提取变量:
- 使用正则匹配
- 举例说明
上面的例子中,通过给出 podname 的真实示例,可以帮助 LLM 从输出的文本信息中提取流水线需要的变量。
5. 事件驱动的 AI Agent
前面的文章中我提到过,Copilot 是人驱动,人负责的;AI Agent 是程序自行驱动,程序负责的。
通过上面的对齐方式,其实不仅限于运维领域,在其他领域也可以基于流水线化的 AI 任务来快速对齐 LLM 实现 Copilot 的功能。难点在于,你需要实现该领域的 Ops Server、Ops Controller 类似的领域抽象和组件能力。这不是一件容易的事情。
之前开发 Ops 的契机来自于工作需求,我需要维护很多机器、集群,批量进行运维和配置。受益于团队的包容,我能边开发 Ops 项目,边进行大量运维任务的尝试,最终 Ops 逐步稳定下来,在生产中得以应用。在迭代的过程中,因为 Ops 项目的 Bug 差点搞出事故,这部分我在博文中也有所记录,之后我就愈加谨慎对待 Ops 的更新。
回到 AI Agent,现在也有一个基于工作岗位上的生产需求,自动处理线上的 AI 基础设施故障。
实际上,Copilot 与 AI Agent 只有一墙之隔,无非就是转被动为主动,用程序代替人驱动 Copilot。
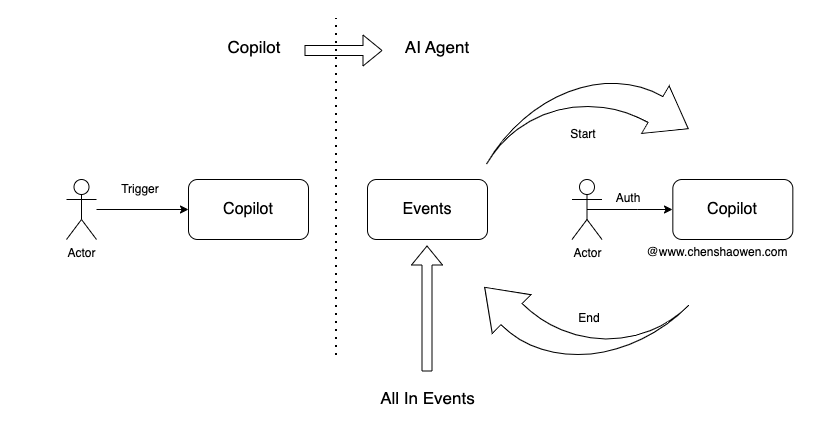
如上图,Copilot 是基于人的输出来触发,分析人的输出,执行任务,将结果反馈给人。但人的输出是从哪里来的呢?主要有两种:
- 从 0 到 1,原始需求发起方
自主原创的部分,比如我要创建一个命名空间 Namespace。那么这个想法,会被记录在哪里,这个记录的源头,能不能作为一个事件源,自动的触发 Copilot 执行创建命名空间的任务。
- 从 1 到 1,从其他地方拷贝的
从其他地方拷贝的部分,比如一条告警信息,能不能产生一个事件,通知给人,得到确认和授权之后,交给 Copilot 执行。
围绕生产的活动,都可以将其以事件化的形式转给 Copilot,这就是事件驱动的 AI Agent 开发思路。
当然这部分,我也是在实践的早期,因为通过 Ops 也可以做巡检任务。

如上图所示,巡检任务会定时执行,当发现异常时就会产生事件,发送通知,如果将这个事件直接发送给 Copilot,并且 Copilot 已经集成了这种事件的处理方式,那么这个异常就能直接借助 LLM 解决掉,实现对故障处理的完全接管。
6. 总结
本篇主要内容如下:
- Ops Copilot 的重新设计
对 Ops Copilot 进行了重新设计,使其更深入地与 Ops 项目整合,利用大型语言模型(LLM)来增强运维任务的自动化。
- 流水线化的 AI 任务
通过将 AI 任务流水线化,借鉴在不同 CI/CD 工具和工作流项目中的经验,在 Ops Copilot 中实现了任务的组装和执行。
- 事件驱动的 AI Agent
将人类操作转化为程序驱动的事件,可以促进 Copilot 向 AI Agent 的演进,实现程序对环境的完全接管。
