1. 磁盘处理
1.1 查看磁盘
Disk /dev/nvme1n1: 3.91 TiB, 4294967296000 bytes, 8388608000 sectors
1.2 组建 RAID0
如果有多块小盘,更好的方式是组建一个 RAID0,这样不仅能获得更大的存储目录,还能获得更快的速度。
1
| mdadm --create --verbose /dev/md0 --level=0 --raid-devices=3 /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1
|
1
| mdadm --detail /dev/md0
|
1.3 挂载磁盘
1
| mkfs.xfs -f /dev/nvme1n1
|
xfs 适合大文件处理, ext4 适合中小文件处理。
如果是 RAID0 可以执行 mkfs.xfs -f /dev/md0 。
1
2
| UUID=$(blkid -s UUID -o value /dev/nvme1n1)
echo $UUID
|
1
| grep -q "$UUID" /etc/fstab || echo "UUID=$UUID /data xfs defaults,nofail 0 2" >> /etc/fstab
|
1
2
3
| df -h |grep data
/dev/nvme1n1 4.0T 28G 3.9T 1% /data
|
2. 安装驱动
2.1 查看系统是否识别显卡
1
2
3
4
| lspci | grep -i vga
03:00.0 VGA compatible controller: NVIDIA Corporation GP102 [TITAN X] (rev a1)
0a:00.0 VGA compatible controller: Matrox Electronics Systems Ltd. G200eR2 (rev 01)
|
识别出显卡为 NVIDIA 的 TITAN X。
2.2 禁用 nouveau
如果有输出,说明 nouveau 已经加载,需要禁用。如果没有输出,则可以跳过此操作。
- 关闭自动更新
1
| sed -i.bak 's/1/0/' /etc/apt/apt.conf.d/10periodic
|
编辑配置文件:
1
| vim /etc/apt/apt.conf.d/50unattended-upgrades
|
去掉以下内容的注释
1
2
3
4
| Unattended-Upgrade::Package-Blacklist {
"linux-image-*";
"linux-headers-*";
};
|
- 编辑系统 blacklist
1
| vim /etc/modprobe.d/blacklist-nouveau.conf
|
添加以下配置禁用 nouveau
1
2
| blacklist nouveau
options nouveau modeset=0
|
- 更新 initramfs
- 重启系统
- 编辑系统 blacklist
1
| vim /etc/modprobe.d/blacklist-nouveau.conf
|
添加配置禁用 nouveau
1
2
| blacklist nouveau
options nouveau modeset=0
|
- 更新 initramfs
1
2
| mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bak
dracut /boot/initramfs-$(uname -r).img $(uname -r)
|
- 重启系统
此时不应该有输出。
2.3 安装驱动
1
| apt install lftp python ceph-fuse nfs-common infiniband-diags make -y
|
1
2
| apt install build-essential gcc-9 g++-9
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 90 --slave /usr/bin/g++ g++ /usr/bin/g++-9 --slave /usr/bin/gcov gcov /usr/bin/gcov-9
|
访问 https://www.nvidia.com/en-us/drivers/ 选择对应的驱动版本下载。这里以 Linux 64-bit 的 TITAN X 驱动为例:
1
| wget https://us.download.nvidia.com/XFree86/Linux-x86_64/535.183.01/NVIDIA-Linux-x86_64-535.183.01.run
|
去 us 站点下载速度会慢点,但是 wget 不会 404。
1
2
| chmod +x NVIDIA-Linux-x86_64-535.146.02.run
./NVIDIA-Linux-x86_64-535.146.02.run --accept-license --silent --no-x-check --no-nouveau-check --disable-nouveau --no-opengl-files
|
另外一种是使用 apt 安装
1
| wget https://us.download.nvidia.com/tesla/550.144.03/nvidia-driver-local-repo-ubuntu2204-550.144.03_1.0-1_amd64.deb
|
1
2
3
4
5
| cat > /etc/apt/preferences.d/nvidia <<EOF
Package: *
Pin: release o=NVIDIA
Pin-Priority: 550
EOF
|
1
| dpkg -i nvidia-driver-local-repo-ubuntu2204-535.230.02_1.0-1_amd64.deb
|
1
| apt-get install -y nvidia-driver-550
|
常用驱动
580.126.09 适用 50、40 系列显卡
https://us.download.nvidia.com/XFree86/Linux-x86_64/580.126.09/NVIDIA-Linux-x86_64-580.126.09.run
2.4 关闭 ECC 校验
对于推理的设备,可以关闭 ECC 校验,以获得更多的显存使用。
1
| for GPU in $(nvidia-smi --query-gpu=index --format=csv,noheader); do nvidia-smi -i $GPU -e 0; done
|
3. 安装 nvidia-container-runtime
3.1 安装 Containerd
1
2
| apt-get update
apt-get install -y ca-certificates curl gnupg lsb-release
|
如果是国内:
1
2
| mkdir -p /etc/apt/keyrings
curl -fsSL https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
|
1
2
3
4
| echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu/ \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
|
如果是海外:
1
2
| mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | gpg --dearmor -o /etc/apt/keyrings/docker.gpg
|
1
2
3
| echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | tee /etc/apt/sources.list.d/docker.list > /dev/null
|
1
2
| apt update
apt install containerd.io=1.6.31-1
|
1
2
| mkdir -p /etc/containerd
containerd config default > /etc/containerd/config.toml
|
1
2
3
4
| sed -i 's#root = "/var/lib/containerd"#root = "/data/containerd"#g' /etc/containerd/config.toml
sed -i 's#state = "/run/containerd"#state = "/data/run/containerd"#g' /etc/containerd/config.toml
sed -i 's#sandbox_image = "registry.k8s.io/pause:[^"]*"#sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9"#g' /etc/containerd/config.toml
sed -i 's#SystemdCgroup = false#SystemdCgroup = true#g' /etc/containerd/config.toml
|
1
| systemctl restart containerd
|
3.2 安装 nvidia-container-runtime
国内如果访问不了可以安装 nvidia-container-toolkit
1
2
3
4
5
6
| apt-key adv --keyserver keyserver.ubuntu.com --recv-keys DDCAE044F796ECB0
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://mirrors.ustc.edu.cn/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://nvidia.github.io#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://mirrors.ustc.edu.cn#g' | \
tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
apt update && apt install nvidia-container-toolkit
|
海外可以直接使用 nvidia-container-runtime
1
2
3
4
| curl -s -L https://nvidia.github.io/nvidia-container-runtime/gpgkey | apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.list | tee /etc/apt/sources.list.d/nvidia-container-runtime.list
apt-get update
|
1
| apt-get install -y nvidia-container-runtime
|
1
2
| distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.repo | tee /etc/yum.repos.d/nvidia-container-runtime.repo
|
1
| yum install -y nvidia-container-runtime
|
3.3 Docker 配置
配置 Docker 开启 GPU 支持
1
| vim /etc/docker/daemon.json
|
添加以下内容:
1
2
3
4
5
6
7
8
9
10
| {
"default-runtime": "nvidia",
"data-root": "/data/docker",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
|
1
2
| systemctl daemon-reload
systemctl restart docker
|
1
| docker run --rm --gpus 1 $IMAGE nvidia-smi
|
此时可以看到输出的 GPU 信息。
3.4 Containerd 配置
1
| vim /etc/containerd/config.toml
|
在与 plugins."io.containerd.grpc.v1.cri".containerd.runtimes 中添加:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"
CriuImagePath = ""
CriuPath = ""
CriuWorkPath = ""
IoGid = 0
IoUid = 0
NoNewKeyring = false
NoPivotRoot = false
Root = ""
ShimCgroup = ""
SystemdCgroup = true
|
将默认的 runtime 设置为 nvidia
1
2
| [plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "nvidia"
|
也可以直接用 sed 替换
1
| sed -i 's/default_runtime_name = "runc"/default_runtime_name = "nvidia"/g' /etc/containerd/config.toml
|
1
2
| systemctl daemon-reload
systemctl restart containerd
|
1
| nerdctl run --rm --gpus 1 $IMAGE nvidia-smi
|
CUDA 是 NVIDIA 推出的通用并行计算架构,用于在 GPU 上进行通用计算。CUDA Toolkit 是 CUDA 的开发工具包,包含了编译器(NVCC)、库、调试器等工具。
4.1 检查系统是否支持
参考 https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#system-requirements 有最新的 CUDA 对 CPU 架构、操作系统、GCC 版本、GLIBC 版本的依赖要求。
1
| uname -m && cat /etc/os-release
|
4.2 兼容性说明
使用 nvidia-smi 命令可以看到一个 CUDA 的版本号,但这个版本号是 CUDA driver libcuda.so 的版本号,不是 CUDA Toolkit 的版本号。
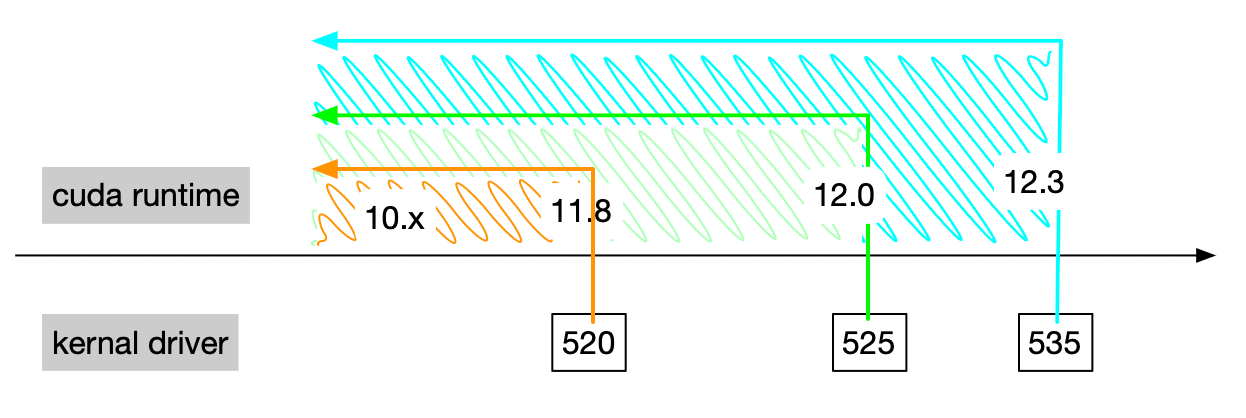
如上图 CUDA driver 是向后兼容的,即支持之前的 CUDA Toolkit 版本。
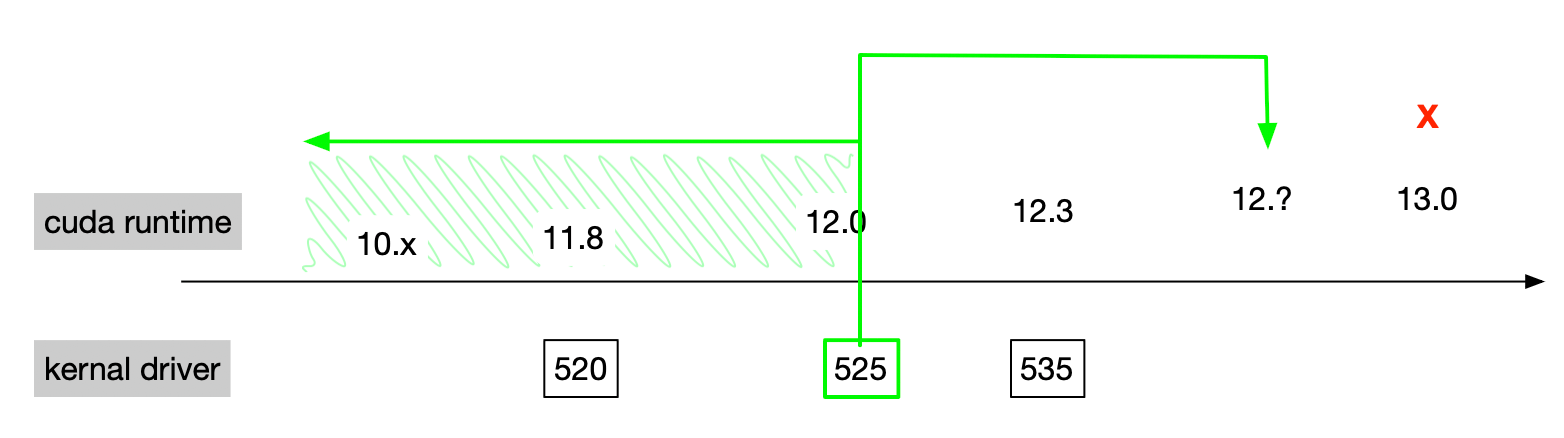
如上图,CUDA driver 支持向前的次要版本兼容,即大版本号相同就支持。参考[2]。
4.3 安装 CUDA
前往 https://developer.nvidia.com/cuda-downloads 选择对应的版本下载。这里以 Ubuntu 20.04 的 runfile(local) 为例:
1
| wget https://developer.download.nvidia.com/compute/cuda/12.3.1/local_installers/cuda_12.3.1_545.23.08_linux.run
|
1
| sh cuda_12.3.1_545.23.08_linux.run
|
增加以下内容:
1
2
3
| export PATH=$PATH:$PATH:/usr/local/cuda/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda
|
使环境变量立即生效:
5. 安装 cuDNN
cuDNN 是 NVIDIA 基于 CUDA 开发的深度神经网络加速库。
前往 https://docs.nvidia.com/deeplearning/cudnn/backend/latest/reference/support-matrix.html 查看 cuDNN 与 CUDA、Driver、操作系统的兼容性是否满足要求。
前往 https://developer.nvidia.com/rdp/cudnn-archive 下载对应的版本,选择 Local Installer for Linux x86_64 (Tar) ,会得到一个 tar.xz 的压缩包。
1
| tar -xvf cudnn-linux-*-archive.tar.xz
|
1
2
3
| cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda/include
cp -P cudnn-*-archive/lib/libcudnn* /usr/local/cuda/lib64
chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
|
6. 开启持久模式
使用 nvidia-smi -pm 1 能够开启持久模式,但重启后会失效,同时使用 nvidia-smi 的方式已经被归档,推荐使用 nvidia-persistenced 常驻进程。
开启持久模式之后,驱动一直会被加载,会消耗更多能源,但能有效改善各种显卡故障。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| cat <<EOF > /lib/systemd/system/nvidia-persistenced.service
[Unit]
Description=NVIDIA Persistence Daemon
After=syslog.target
[Service]
Type=forking
PIDFile=/var/run/nvidia-persistenced/nvidia-persistenced.pid
Restart=always
ExecStart=/usr/bin/nvidia-persistenced --verbose
ExecStopPost=/bin/rm -rf /var/run/nvidia-persistenced/*
TimeoutSec=300
[Install]
WantedBy=multi-user.target
EOF
|
1
| systemctl start nvidia-persistenced
|
1
| systemctl status nvidia-persistenced
|
1
| systemctl enable nvidia-persistenced
|
7. 安装 NVLink 和 NVSwitch 驱动
如果装配了 NVLink 或者 NVSwitch ,还需要安装 nvidia-fabricmanager,否则无法正常工作。
在 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ 找到合适的版本。
1
| wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/nvidia-fabricmanager-535_535.129.03-1_amd64.deb
|
1
| apt install ./nvidia-fabricmanager-535_535.129.03-1_amd64.deb
|
- 启动 nvidia-fabricmanager 服务
1
| systemctl start nvidia-fabricmanager
|
- 查看 nvidia-fabricmanager 服务
1
| systemctl status nvidia-fabricmanager
|
1
| systemctl enable nvidia-fabricmanager
|
8. 安装 InfiniBand 驱动
在 https://network.nvidia.com/products/infiniband-drivers/linux/mlnx_ofed/ 找到合适的系统版本。
1
| wget https://content.mellanox.com/ofed/MLNX_OFED-5.8-7.0.6.1/MLNX_OFED_LINUX-5.8-7.0.6.1-ubuntu20.04-x86_64.tgz
|
1
2
3
| tar zxf MLNX_OFED_LINUX-5.8-7.0.6.1-ubuntu20.04-x86_64.tgz
cd MLNX_OFED_LINUX-5.8-7.0.6.1-ubuntu20.04-x86_64
./mlnxofedinstall --with-nfsrdma
|
然后重启机器,可以查看驱动状态
1
2
3
4
5
6
7
8
9
10
11
| systemctl status openibd
● openibd.service - openibd - configure Mellanox devices
Loaded: loaded (/lib/systemd/system/openibd.service; enabled; vendor preset: enabled)
Active: active (exited) since Mon 2024-03-11 15:30:58 CST; 1 weeks 0 days ago
Docs: file:/etc/infiniband/openib.conf
Process: 2261 ExecStart=/etc/init.d/openibd start bootid=65648015406c4b88b831c8b907ad4ec6 (code=exited, status=0/SUCCESS)
Main PID: 2261 (code=exited, status=0/SUCCESS)
Tasks: 0 (limit: 618654)
Memory: 24.6M
CGroup: /system.slice/openibd.service
|
通过 ibstat 可以查看设备信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| ibstat
ibstat
CA 'mlx5_0'
CA type: MT4123
Number of ports: 1
Firmware version: 20.35.1012
Hardware version: 0
Node GUID: 0x946dae03008bcc68
System image GUID: 0x946dae03008bcc68
Port 1:
State: Active
Physical state: LinkUp
Rate: 200
Base lid: 124
LMC: 0
SM lid: 1
Capability mask: 0xa651e848
Port GUID: 0x946dae03008bcc68
Link layer: InfiniBand
CA 'mlx5_1'
CA type: MT4123
Number of ports: 1
Firmware version: 20.35.1012
Hardware version: 0
Node GUID: 0x946dae03008bcc3c
System image GUID: 0x946dae03008bcc3c
Port 1:
State: Active
Physical state: LinkUp
Rate: 200
Base lid: 126
LMC: 0
SM lid: 1
Capability mask: 0xa651e848
Port GUID: 0x946dae03008bcc3c
Link layer: InfiniBand
|
9. 加入 K8s 集群
9.1 修改 Hostname
1
| export HOSTNAME=k8s-worker-gpu-01
|
1
| hostnamectl set-hostname ${HOSTNAME}
|
9.2 初始化内核参数
1
| opscli task -f ~/.ops/tasks/set-host.yaml
|
9.3 安装 K8s 基础组件
https://developer.aliyun.com/mirror/kubernetes/ 1.28 以下版本添加
1
| curl -fsSL https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo gpg --dearmour -o /etc/apt/trusted.gpg.d/kubernetes-aliyun.gpg
|
1
2
3
| cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
|
1
2
| mkdir -p /data/kubelet
ln -s /data/kubelet /var/lib/kubelet
|
1
| export K8S_VERSION=1.27.6
|
1
| apt-get install kubeadm=${K8S_VERSION}-00 kubelet=${K8S_VERSION}-00 kubectl=${K8S_VERSION}-00 -y
|
1
| vim /var/lib/kubelet/kubeadm-flags.env
|
添加以下内容:
1
| --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9 --resolv-conf=/etc/resolv.conf --authentication-token-webhook=true --authorization-mode=Webhook --system-reserved=cpu=1,memory=2Gi --kube-reserved=cpu=1,memory=2Gi
|
在上面的 kubelet 配置中添加 --node-ip= 参数指定节点 IP 地址,--hostname-override= 参数指定节点 Hostname。
1
| --node-ip=x.x.x.x --hostname-override=my-hostname
|
如果是 Flannel 需要在 DeamonSet 中添加 --iface= 参数指定网卡。
1
2
3
4
5
6
7
| containers:
- args:
- --ip-masq
- --kube-subnet-mgr
- --iface-regex=^10\.0\.
command:
- /opt/bin/flanneld
|
1
2
3
4
| systemctl enable kubelet
systemctl daemon-reload
systemctl restart kubelet
systemctl status kubelet
|
9.4 加入集群
在 master 节点生成 token
1
| kubeadm token create --print-join-command
|
1
2
| kubeadm join x.x.x.x:6443 --token xxx \
--discovery-token-ca-cert-hash sha256:xxx
|
如果是 Docker 环境,需要走一遍 Containerd 的配置,然后带上 --cri-socket 参数。
1
| --cri-socket unix:///run/containerd/containerd.sock -v5
|
如果报错 [ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables does not exist 就执行一下。
1
2
3
| modprobe br_netfilter
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables
echo 1 > /proc/sys/net/ipv4/ip_forward
|
9.5 创建测试的 Pod
1
| export IMAGE=nvidia/cuda:12.3.2-base-ubuntu22.04
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| kubectl create -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
generateName: gpu-demo-
labels:
app: gpu-demo
spec:
nodeName: ${HOSTNAME}
containers:
- name: gpu-demo
image: ${IMAGE}
command: ["nvidia-smi"]
resources:
requests:
tencent.com/vcuda-core: 100
limits:
tencent.com/vcuda-core: 100
EOF
|
1
| kubectl logs -l app=gpu-demo
|
1
| kubectl delete pod -l app=gpu-demo
|
10. 部署 k8s-rdma-shared-dev-plugin
为了让 Kubernetes 能够发现 RDMA 设备,比如 IfiniBand ,并且被多个 Pod 使用,需要安装 k8s-rdma-shared-dev-plugin。
- 安装 k8s-rdma-shared-dev-plugin
1
| kubectl apply -f https://raw.githubusercontent.com/shaowenchen/ops-hub/master/network/k8s-rdma-shared-dev-plugin.yaml
|
1
| kubectl -n kube-system edit cm rdma-devices
|
在 spec 中配置 rdma/ib 就可以使用了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| spec:
containers:
- command:
- /bin/sh
- -c
- mkdir -p /var/run/sshd; /usr/sbin/sshd;bash llama_distributed_v3.0_check.sh
resources:
limits:
cpu: "64"
memory: 950Gi
rdma/ib: "8"
tencent.com/vcuda-core: "800"
requests:
cpu: "64"
memory: 950Gi
rdma/ib: "8"
tencent.com/vcuda-core: "800"
|
11. 性能优化
临时设置 CPU 锁频高性能模式
1
2
3
| for cpu in /sys/devices/system/cpu/cpu[0-9]*; do
echo performance | sudo tee $cpu/cpufreq/scaling_governor
done
|
永久设置 CPU 锁频高性能模式
1
| apt-get install tuned -y
|
1
| tuned-adm profile throughput-performance
|
查看 CPU 运行模式
1
| cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
|
关闭或调整 THP(透明大页)自动整理,防止内核后台 defrag 导致延迟卡顿,造成周期性延迟抖动。
临时关闭 THP
1
2
| echo defer > /sys/kernel/mm/transparent_hugepage/defrag
echo 'defer+madvise' > /sys/kernel/mm/transparent_hugepage/defrag
|
永久关闭 THP
1
| echo never > /sys/kernel/mm/transparent_hugepage/defrag
|
查看 THP 状态
1
| cat /sys/kernel/mm/transparent_hugepage/defrag
|
- 网卡队列(丢包问题),缺点是缓冲区增加,网络延时增加
默认值通常是 256 或 512,对于高速万兆/百兆网卡来说太小。
临时设置网卡队列
1
2
| ethtool -G eth0 rx 8192 tx 8192
ethtool -G eth1 rx 8192 tx 8192
|
永久设置网卡队列
1
2
3
4
5
6
| cat >/etc/ethtool-ring.sh <<'EOF'
#!/bin/bash
ethtool -G eth0 rx 8192 tx 8192 || true
ethtool -G eth1 rx 8192 tx 8192 || true
EOF
chmod +x /etc/ethtool-ring.sh
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| cat >/etc/systemd/system/ethtool-ring.service <<'EOF'
[Unit]
Description=Set NIC ring buffer size
After=network-online.target
Wants=network-online.target
[Service]
Type=oneshot
ExecStart=/etc/ethtool-ring.sh
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable ethtool-ring.service
systemctl start ethtool-ring.service
|
查看网卡队列
1
2
| ethtool -g eth0
ethtool -g eth1
|
- 机器 clocksource hpet 改成 tsc,缺点是老旧 CPU 或多 CPU 系统上可能存在不同步问题
TSC(Time Stamp Counter) 是 CPU 内建计时器,访问极快、延迟低(纳秒级)
临时设置 clocksource
1
| echo tsc | tee /sys/devices/system/clocksource/clocksource0/current_clocksource
|
永久设置 clocksource
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| cat >/etc/systemd/system/clocksource-tsc.service <<'EOF'
[Unit]
Description=Set clocksource to tsc
After=multi-user.target
[Service]
Type=oneshot
ExecStart=/bin/sh -c 'echo tsc > /sys/devices/system/clocksource/clocksource0/current_clocksource'
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable clocksource-tsc.service
systemctl start clocksource-tsc.service
|
查看当前的 clocksource
1
| cat /sys/devices/system/clocksource/clocksource0/current_clocksource
|
一般需要在 BMC(带外管理)或 BIOS 里调节。
12. 参考
- https://nvidia.github.io/nvidia-container-runtime/
- https://tianzhipeng-git.github.io/2023/11/21/cuda-version.html
