1. 什么是 MPI
MPI,Message Passing Interface 消息传递接口,是一种用于并行计算的通信协议。
MPI 提供了一组标准化的接口,用于在不同的计算节点之间传输数据,广泛应用于科学计算、机器学习、深度学习等领域。
MPI 有多个实现,常用实现有 MPICH 和 OpenMPI。MPICH 是由 Argonne 实验室主导开发的,是各种商业定制版本的基础,因此不能简单认为 MPICH 是一个产品,而是包含一系列衍生的版本,比如 MVAPICH、Intel MPI 等。OpenMPI 是一个由多个研究机构(包括 UTK、IU、Cisco、NVIDIA 等)联合开发的的版本。
具体选择可以参考:
适合大多数 Linux 集群,尤其是需要高性能网络支持(如 InfiniBand、ROCE)和 GPU 支持的场景。常用于 HPC 和深度学习集群。
通用的 Linux 系统高兼容性选项,适用于标准 MPI 应用。若系统希望在不同 MPI 实现之间迁移,MPICH 是稳妥的选择。
基于 MPICH,专为高性能网络(如 InfiniBand 和 RDMA)优化,适合有高网络带宽需求的科学计算任务和 GPU 任务。
专门针对 Intel 硬件进行了优化,适合 Intel 处理器及 Intel Omni-Path 网络,支持主流的 Linux 系统。
2. MPI 通信原语
2.1 点对点 P2P
一个进程与另一个指定进程的通信方式。
1
2
3
4
5
6
7
| MPI_Send(
void* data,
int count,
MPI_Datatype datatype,
int destination,
int tag,
MPI_Comm communicator)
|
向指定的进程发送指定数量的数据。
1
2
3
4
5
6
7
8
| MPI_Recv(
void* data,
int count,
MPI_Datatype datatype,
int source,
int tag,
MPI_Comm communicator,
MPI_Status* status)
|
从指定的进程接收指定数量的数据。
2.2 集合通信 CC
一个进程和所有进程的通信方式。
等待所有进程到达某个点。
1
| MPI_Barrier(MPI_Comm communicator)
|
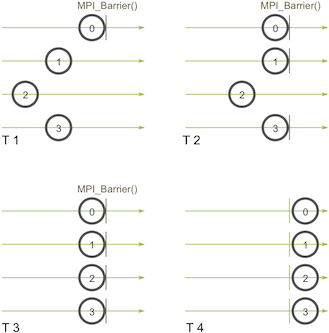
进程 0 在时间点 T1 调用了 MPI_Barrier 之后,需要等待全部进程到达 MPI_Barrier 调用的位置,才能够同时继续执行。
1
2
3
4
5
6
| MPI_Bcast(
void* data,
int count,
MPI_Datatype datatype,
int root,
MPI_Comm communicator)
|
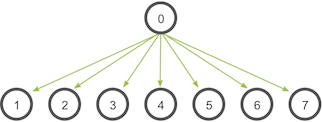
root 进程 0 将向所有进程发送一份数据。
1
2
3
4
5
6
7
8
9
| MPI_Scatter(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)
|
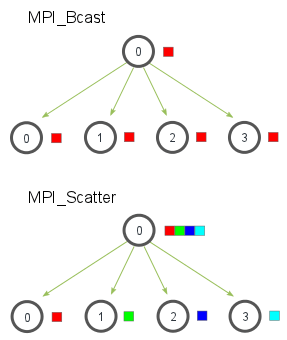
不同于 boradcast 将数据完整副本发送给所有进程,scatter 将数据分割成多份,发送给不同的进程。
1
2
3
4
5
6
7
8
9
| MPI_Gather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)
|
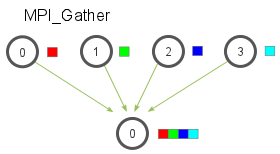
与 scatter 相反,gather 将多份数据接收到一个进程。
1
2
3
4
5
6
7
8
| MPI_Allgather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
MPI_Comm communicator)
|
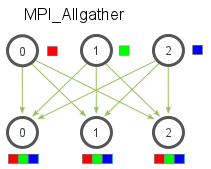
allgather 不需要指定 root,全部的进程会收到其他所有进程的数据。
1
2
3
4
5
6
7
8
| MPI_Reduce(
void* send_data,
void* recv_data,
int count,
MPI_Datatype datatype,
MPI_Op op,
int root,
MPI_Comm communicator)
|
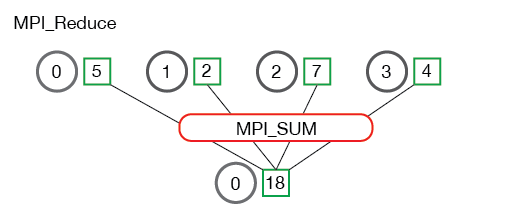
在进行 reduce 操作时,需要指定一个 op 操作称之为归约。上图中的归约操作就是求和。
1
2
3
4
5
6
7
| MPI_Allreduce(
void* send_data,
void* recv_data,
int count,
MPI_Datatype datatype,
MPI_Op op,
MPI_Comm communicator)
|
不同于 reduce,allreduce 不需要指定 root,所有进程都会收到归约后的结果。
3. 安装 MPICH\OpenMPI
安装 MPICH 就执行
1
| apt-get install mpich -y
|
安装 OpenMPI 就执行
1
| apt-get install openmpi-bin -y
|
会得到编译命令和运行命令,无论是安装 MPICH 还是 OpenMPI,都会得到类似的命令行工具。
3.1 MPI 编译命令
使用 C 编译器编译 MPI 程序,确保编译出的程序可以使用 MPI 通信库。
使用 C++ 编译器编译 MPI 程序。
使用不同 Fortran 编译器编译 MPI 程序。
3.2 MPI 运行命令
运行 MPI 程序,管理 MPI 进程的启动。
与 mpirun 类似,但是更加符合 MPI 标准。
针对特定环境、使用特定工具的 MPI 程序管理器。
4. MPI 程序示例
4.1 编写 MPI Python 程序
保存如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| from mpi4py import MPI
import numpy as np
import socket
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
# 获取当前进程所在主机的主机名
hostname = socket.gethostname()
# 每个进程生成一个随机数并包装成 numpy 数组
local_data = np.random.random(1) # 包装成一个 numpy 数组
print(f"Process {rank} on host {hostname} has local data: {local_data[0]}")
# 使用 gather 收集所有进程的数据
all_data = comm.gather(local_data[0], root=0)
# 创建用于 Allreduce 的缓冲区
global_data = np.zeros(1, dtype='d') # 初始化全局数据为零,类型为 double
comm.Allreduce(local_data, global_data, op=MPI.SUM)
# 只在 rank 0 上输出结果
if rank == 0:
print(f"All process data: {all_data}")
print(f"The sum of all data is: {global_data[0]}")
|
在一些集合通信的场景下,有时会针对某个进程进行一些特殊处理,就会使用 rank 来判断当前进程的编号符合条件时,执行操作。
4.2 配置免密
编辑 /etc/hosts 文件,添加主机名和 IP 地址的映射。
1
2
3
| x.x.x.x host-1
x.x.x.x host-2
x.x.x.x host-3
|
1
2
3
| scp /root/.ssh/id_rsa /root/.ssh/id_rsa.pub host-1:/root/.ssh/
scp /root/.ssh/id_rsa /root/.ssh/id_rsa.pub host-2:/root/.ssh/
scp /root/.ssh/id_rsa /root/.ssh/id_rsa.pub host-3:/root/.ssh/
|
4.3 安装依赖
全部主机应该安装相同的 MPI 实现和版本。
1
| opscli shell -i host-1,host-2,host-3 --content "apt-get install openmpi-bin libopenmpi-dev -y"
|
这里需要额外安装一个依赖包 libopenmpi-dev,用于编译安装 mpi4py。
1
| opscli shell -i host-1,host-2,host-3 --content "pip install mpi4py numpy"
|
1
2
| scp /data/mpi.py host-2:/data/
scp /data/mpi.py host-3:/data/
|
4.4 创建 Hostfile 文件
1
2
3
4
5
| cat > hostfile <<EOF
host-1 slots=1
host-2 slots=1
host-3 slots=1
EOF
|
这里的 slots 表示每个主机能启动的最大进程数。一般情况下,slots 为 CPU 核心数。
除了使用 hostfile 文件指定主机,还可以使用 -host 参数指定主机及 slots 值。
1
2
| -host host-1 -host host-2 -host host-3
-host host-1:1 -host host-2:1
|
host-1:1 表示 host-1 只能启动一个进程,冒号后面是最大进程数。
4.5 运行 MPI 程序
1
2
3
4
5
6
7
| mpirun --allow-run-as-root -np 3 -hostfile hostfile python3 /data/mpi.py
Process 2 on host host-3 has local data: 0.8237177424830892
Process 0 on host host-1 has local data: 0.4049368708804896
Process 1 on host host-2 has local data: 0.055557219335660935
All process data: [np.float64(0.4049368708804896), np.float64(0.055557219335660935), np.float64(0.8237177424830892)]
The sum of all data is: 1.2842118326992398
|
1
2
3
4
5
6
7
8
| mpirun --allow-run-as-root -np 4 -host host-2:4 python3 /data/mpi.py
Process 1 on host host-2 has local data: 0.57806331374296
Process 0 on host host-2 has local data: 0.10289882095170111
Process 2 on host host-2 has local data: 0.7618555892517183
Process 3 on host host-2 has local data: 0.810980561742528
All process data: [0.10289882095170111, 0.57806331374296, 0.7618555892517183, 0.810980561742528]
The sum of all data is: 2.2537982856889074
|
- mpi 会按照 host 顺序,依次给每个 host 分配 slots 数量的进程
让可用的 slots 数量远大于进程数,观察 MPI 对进程的分配策略。
1
2
3
4
5
6
7
8
| mpirun --allow-run-as-root -np 4 -host host-1:2 -host host-2:4 -host host-3:8 python3 /data/mpi.py
Process 3 on host host-2 has local data: 0.2001460877733756
Process 0 on host host-1 has local data: 0.6559694967423054
Process 2 on host host-2 has local data: 0.43367558731572886
Process 1 on host host-1 has local data: 0.8121368124082778
All process data: [np.float64(0.6559694967423054), np.float64(0.8121368124082778), np.float64(0.43367558731572886), np.float64(0.2001460877733756)]
The sum of all data is: 2.101927984239688
|
实验了很多次,结果都是 host-1 分配 2 个进程,host-2 分配 2 个进程,host-3 没有分配进程。这说明,MPI 是按照提供的主机顺序,依次充分给 host 分配进程。
5. 参考
