1. 数据并行
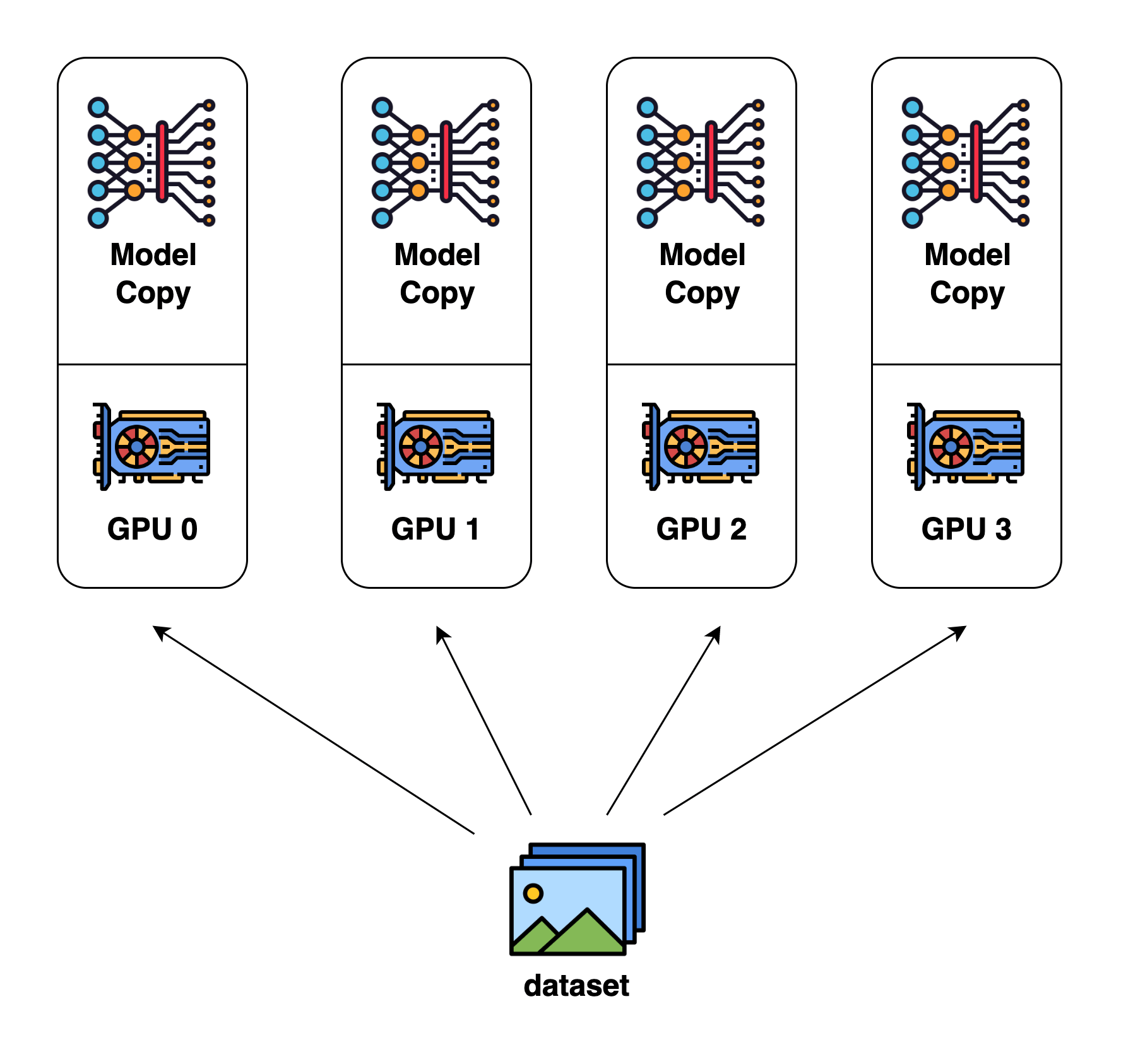
训练步骤:
- master 设备加载模型,并将模型参数复制到每个 worker 设备
- master 设备按照 batch 维度划分训练数据,将每个 batch 传递给每个 worker 设备
- 每个 worker 设备进行训练
- master 设备汇总每个 worker 设备的梯度,更新模型参数
- master 设备广播模型参数到每个 worker 设备,准备下一个 batch 训练
核心思想:
将训练数据按 batch 维度划分,分发到多个 worker 设备上并行计算,从而加速训练过程。每个 worker 完全复制了模型参数,独立进行前向和反向传播计算。最终通过单个 master 设备汇总所有 worker 的梯度,统一更新模型参数并广播回 worker。
适用场景:
- 大规模数据集的训练场景
特点:
- 模型参数量相对较小,可在单 GPU 上加载
- 硬件资源要求相对较低,多 GPU 服务器即可
- 通信开销较小,主要是梯度同步
- 适合大多数 CV/NLP 任务的小模型训练
2. 张量并行
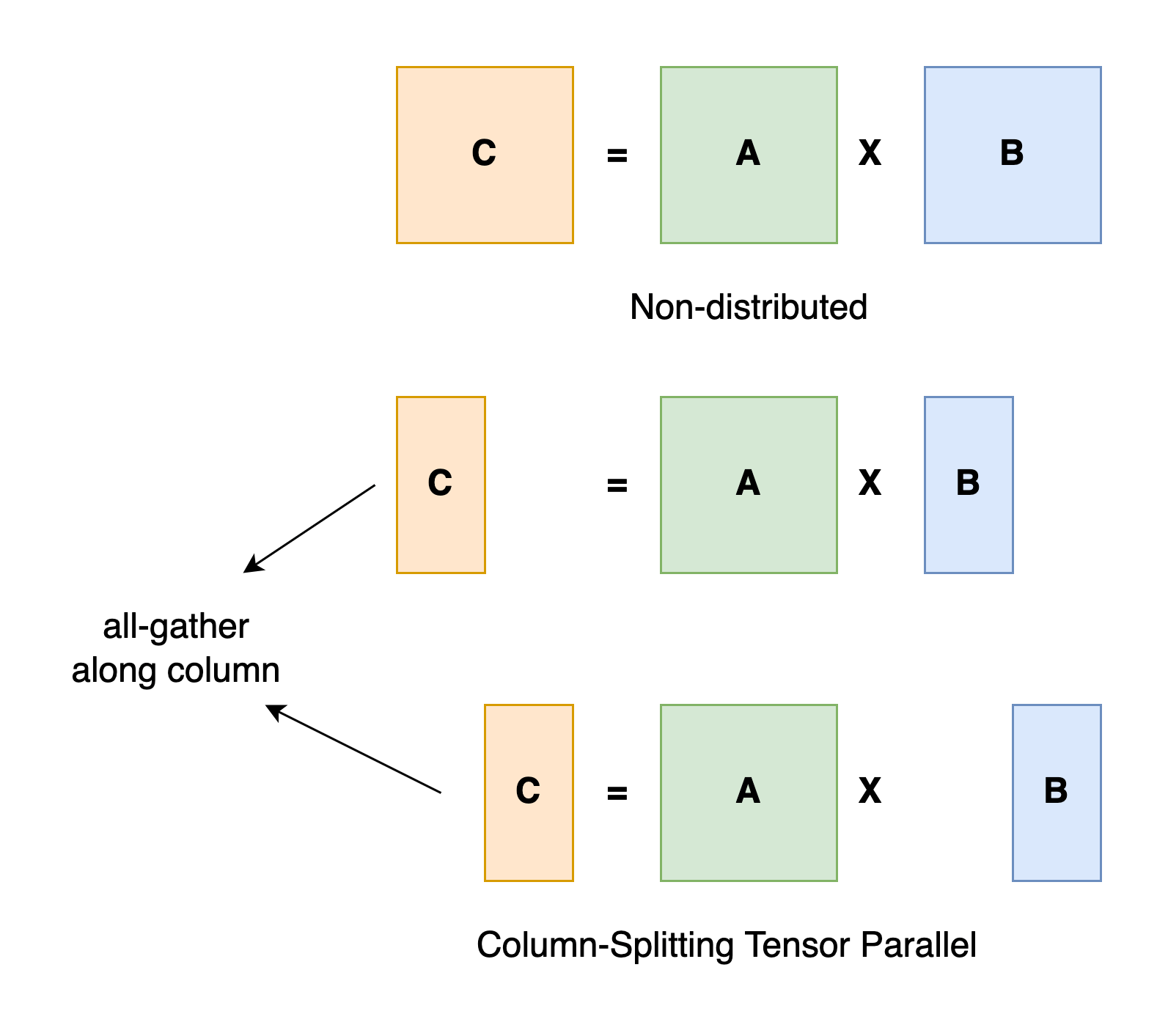
训练步骤:
- 将模型的某些张量(如权重矩阵、激活值等)按行或列划分到不同的设备上
- 在前向传播时,每个设备计算被分配到本设备的那部分张量的运算
- 不同设备之间需要进行激活值的切分和集合操作,以传递部分结果给下一个处理设备
- 所有设备计算完成后,汇总每个设备的梯度,更新对应的模型张量参数。
- 将更新后的模型张量参数分发回各个设备,准备进行下一个 batch 的训练。
核心思想:
将单个层或权重矩阵按行/列划分到不同的 worker 设备上并行计算。这是一种极细粒度的模型并行方式,可以最大化利用所有设备的计算能力,但同时也增加了大量的通信开销。不同 worker 需要频繁切分和集合中间激活值与梯度。
适用场景:
- 极大型模型,且单层参数量巨大的场景,GPT-3 等十亿参数量级的大语言模型
特点:
- 需要集群提供大量 GPU 显存资源
- 通信开销最大,需频繁传递中间结果
- 要合理设计张量划分策略,降低开销
3. 流水线并行
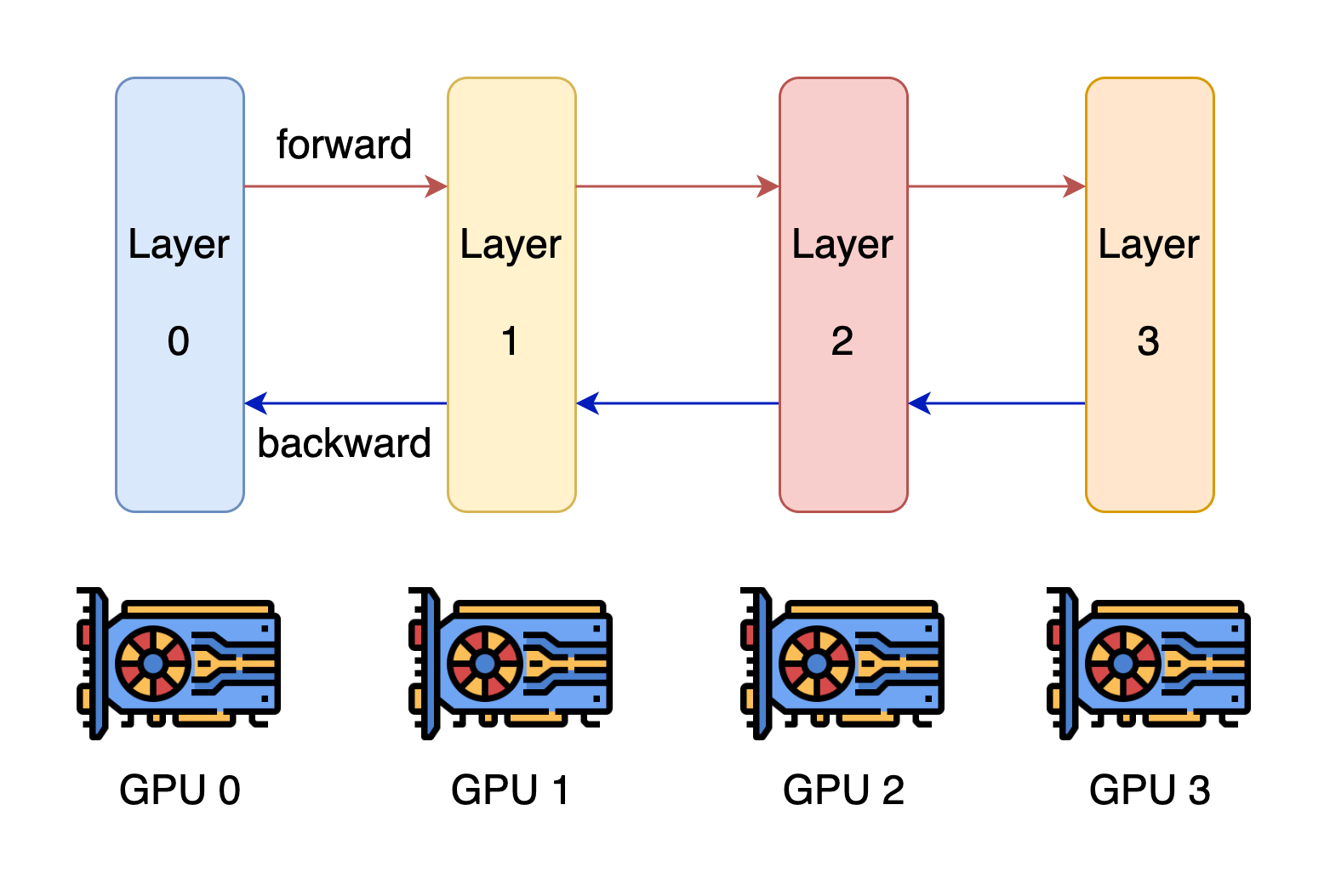
特点:
- 将整个模型按层划分为多个连续的阶段(stage),每个阶段由一个设备负责计算。
- 在每个训练迭代开始时,第一个设备获取一个 batch 的输入数据,并执行前向计算。
- 第一个设备将计算出的中间激活值(activations)传递给第二个阶段的设备。
- 第二个设备接收到激活值后,基于这个输入继续执行前向计算,并将结果传递给下一个阶段,如此类推。
- 直到最后一个阶段完成前向计算,得到最终的输出。
- 基于输出,计算损失函数,并执行反向传播。
- 每个阶段在反向传播时,计算本阶段所需的梯度,并将上游梯度传递给前一个阶段。
- 所有阶段计算完成后,将各自的梯度汇总,更新对应的模型参数。
- 将更新后的模型参数分发到对应的设备,准备进行下一个 batch 的训练迭代。
核心思想:
将模型划分为多个连续的阶段,每个阶段由一个 worker 设备负责。多个 worker 能同时参与计算不同 batch 的前向/反向传播,形成流水线式的并行,从而提高总体吞吐量。不同阶段需要在设备间切分传递激活值和梯度,实现了模型并行与流水线并行的融合。
适用场景:
- 适用于序列数据的长模型训练
特点:
- 模型可相对较大,但每阶段占用显存较小
- 依赖集群提供足够设备资源
- 通信开销适中,主要在阶段切换时传递数据
- 合理划分阶段可最大化流水线并行效率
