1. 为什么是 Transformer
- 全连接的自注意
以往的 RNN 模型,每个单词只能和邻近的单词产生联系,而 Transformer 模型中的 Attention 机制,单词可以和任意位置的单词产生联系,这样就可以捕捉到全局的上下文信息。
- 没有梯度消失问题
RNN 作用在同一个权值矩阵上,使得其最大的特征值小于 1 时,就会出现梯度消失问题。Transformer 中的 Attention 计算是全连接的 softmax 注意力,梯度可以顺畅回传。
- 并行计算
以往的模型是顺序计算,Transformer 支持并行计算,能充分发挥 GPU 的计算能力。
2. 大模型中的 Transformer
一个大模型有多个 Transformer,一个 Transformer 有多个 Encoder Layer 和 Decoder Layer,一个 Encoder Layer 和 Decoder Layer 有多个注意力层(Attention Layer) 和前馈全连接层(Feed Forward Layer)组成。
BERT 模型包含一个 Encoder 模块,由多个 Transformer 编码器堆叠构成。BERT-Base 模型包含 12 个相同的 Transformer Encoder 结构,BERT-Large 模型包含 24 个。
GPT-3 模型包含一个 Decoder 模块,由多个 Transformer 解码器堆叠组成。GPT-3 模型大小从 Small 到 XL,解码器的 Transformer 块数量依次为 12、24、36、48。
3. Transformer 的结构
![]()
每一个 Encoder 的输入是下一层 Encoder 输出,最上一层 Encoder 的输出会输入给每一个 Decoder 层。
每个 Decoder 的输入是下一层 Decoder 输出,最后一层 Decoder 的输出会输入给一个线性层,线性层的输出是一个词表大小的向量,每个位置的值表示该位置的词在当前位置的概率。
Encoder 负责提取输入序列的特征,而 Decoder 是生成输出序列的模块。完整流程可以参考这幅动态图:

3.1 Encoder Layer
![]()
每个 Encoder Layer 由两个子层组成,一个是注意力层(self-Attention Layer),一个是前馈全连接层(Feed Forward Layer)。
- 自注意力层(self-Attention Layer)
自注意力层在编码器中用于捕捉输入序列中不同位置之间的关系。
把输入向量映射到 Query、Key 和 Value 矩阵,进行点积注意力计算,得到单词级注意力表示。
- 前馈全连接层(Feed Forward Layer)
引入非线性性,帮助模型更好地学习输入序列中的特征。
3.2 Decoder Layer
每个 Decoder Layer 由三个子层组成,一个是注意力层(self-Attention Layer),一个是编码器-解码器互注意力层 (Encoder-Decoder Attention Layer),一个是前馈全连接层(Feed Forward Layer)。
- 自注意力层(self-Attention Layer)
计算目标序列中单词之间的相关性,捕捉内部依赖关系。
类似 Encoder 中的 Self-Attention,但仅根据自己的输入计算注意力。
- 编码器-解码器互注意力层 (Encoder-Decoder Attention Layer)
编码器-解码器注意力层在序列到序列模型中连接输入和输出,通过动态调整关注位置,提升模型性能,处理长距离依赖,增强生成准确性。
- 前馈全连接层(Feed Forward Layer)
引入非线性变换,进一步增强表达能力。
3.3 Self-Attention 计算
第一步,这里 X 表示输入,计算查询矩阵 Q,键矩阵 K 和 值矩阵 V
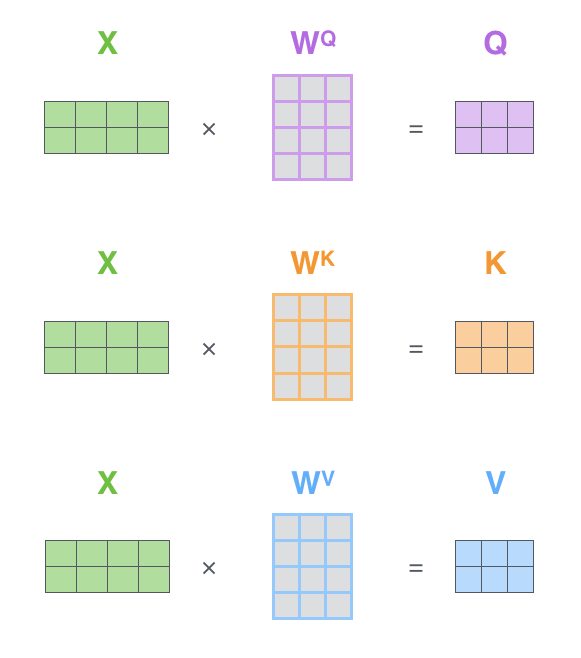
其中
- Wq 用于生成查询(Query)的线性变换矩阵
- Wk 用于生成键(Key)的线性变换矩阵
- Wv 用于生成值(Value)的线性变换矩阵
Wq、Wk 和 Wv 是模型参数,通过训练学习得到。
第二步,计算注意力得分
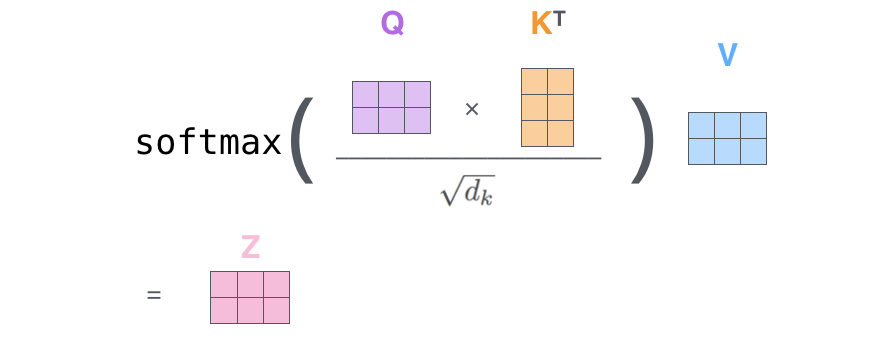
3.4 Word Embedding 矩阵
Word Embedding 矩阵是用于将单词符号表示转换为稠密词向量的矩阵。
在 Transformer 的 Self-Attention 机制中,Query 矩阵、Key 矩阵和 Value 矩阵的大小与模型 Word Embedding 大小相关。一般来说,几百到上千维是较常见的设定。低维无法充分表达语义信息,过高维会带来计算量负担。
在训练过程中,模型不仅会更新权重矩阵,同时还会更新词向量表(Word Embedding 矩阵)。模型通过在大规模语料上预训练,学习到词向量表和各层的权重矩阵,编码语言知识。
在推理阶段,词向量表是固定的,不会再被更新,用于转换输入文本为向量表示。权重矩阵也同样固定,用来执行推理计算,生成最终输出。
也就是说,训练阶段更新了 Embedding 矩阵和权重矩阵,而推理阶段二者均固定不变,仅执行前向计算,不再更新模型参数。
4. 多头注意力机制
相较于单头注意力机制,多头注意力机制可以让模型同时关注不同位置的语义信息,从而提升模型表达能力。
- 头数
常用的多头设计是 8 头或 12 头,也有一些模型使用 16 头。头数越多,每个头可以关注的粒度越细,但计算量也线性增加
- 头与头之间的差别
每个头的 QKV 不同,关注的语义信息也不通,比如一个聚焦主要信息、另一个聚焦背景信息。
利用多头注意力机制,可以实现多模态的大模型,处理不同类型的数据,比如文本、图片、音频等。
