1. 现象
基于 Kubernetes 的 Elasticsearch 频繁重启,导致服务几乎不可用。
- 在导入数据过程中,Pod 的内存使用持续增长
- Pod 内存使用接近 Limit 之后,继续导入就会触发 Pod 异常退出,错误日志
ERROR: Elasticsearch exited unexpectedly - Pod 内存使用率并不会下降,而是维持在 Limit 附近,不久又异常退出
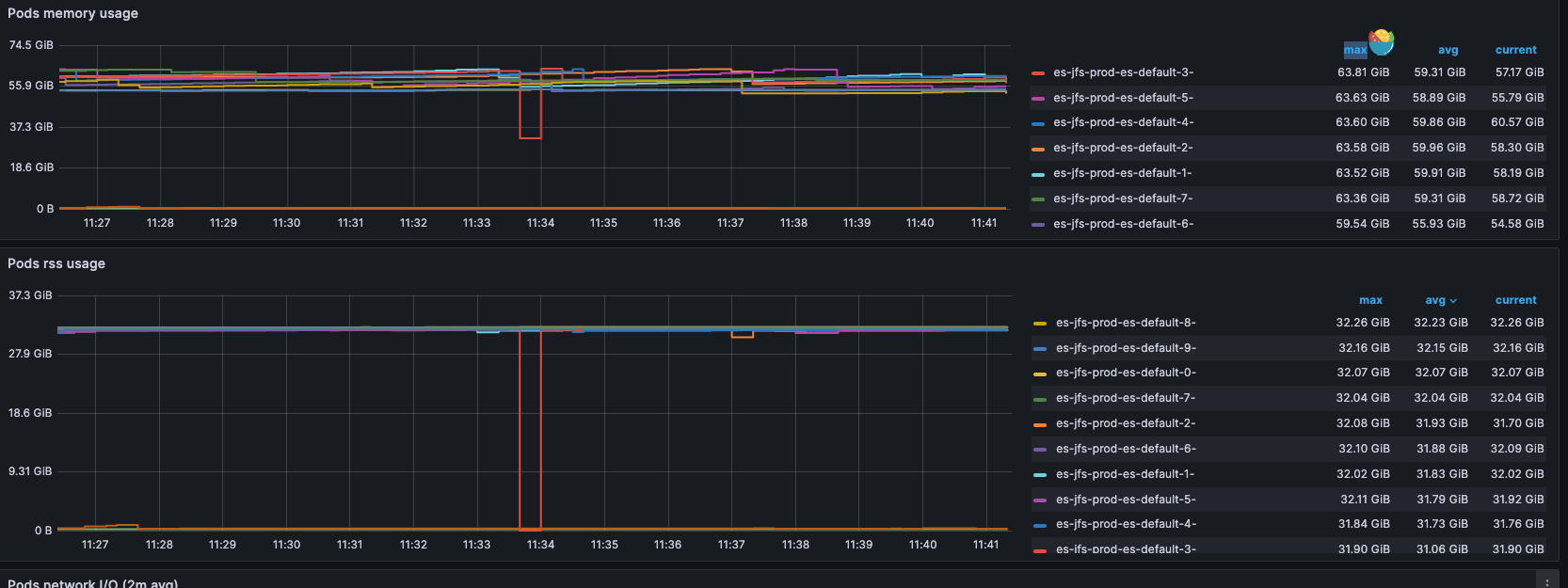
Elasticsearch Pod 内存限制在 64GB,而 JVM 内存限制是 32GB。
2. 查看运行环境
由于 Elasticsearch Pod 频繁出现 Crash、OOMkilled 状态,我对运行环境进行了一次检测。
- 集群及内核版本
| |
系统内核版本、集群版本都挺高。
- 查看节点负载
| |
每个节点的 CPU、内存使用率都很低,没有超过 50%。每个节点都配备有 176C 处理核心、2.0TB 内存。
- 节点内存使用
| |
大量的 Cache 使用引起了我的注意。
3. 原因
容器 Memory OOM 的触发指标是 container_memory_working_set_bytes,其实际组成为 RSS + Cache。
RSS 是指进程当前在物理内存中所占用的空间大小,包括代码、数据和堆栈等。
Cache 是指操作系统用于缓存最近访问过的文件数据的一部分内存。这些数据通常是从磁盘读取的文件内容,被缓存在物理内存中系统中的 Cache 高时,表示系统中有大量的内存被用于缓存最近访问过的文件数据,即大量 IO 操作带来的 Cache 压力。
从上面的监控可以看到 Elasticsearch 的 RSS 使用量一直维持在 32GB,只能是 Cache 不断在增长了。
接着不设置 Limit 观测 Elasticsearch Pod 内存使用情况。
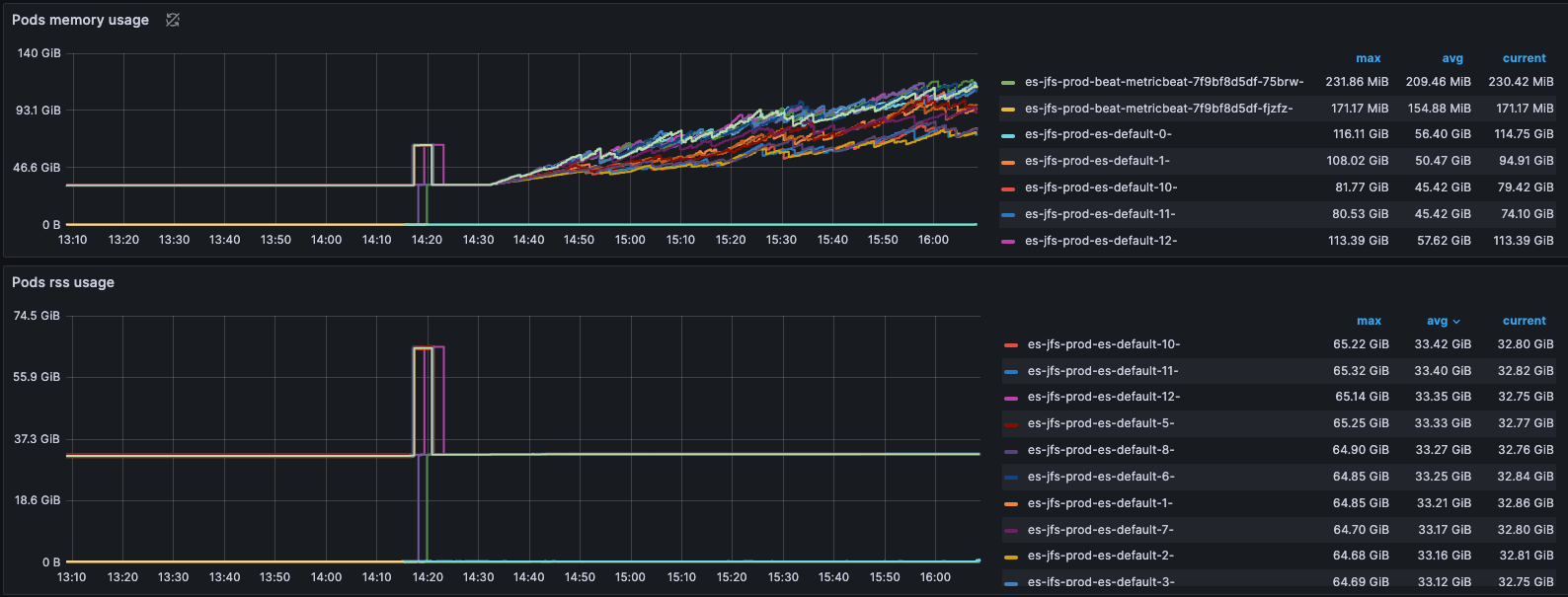
如上图,一直导入数据,Pod 的 Page Cache 使用量持续增长。
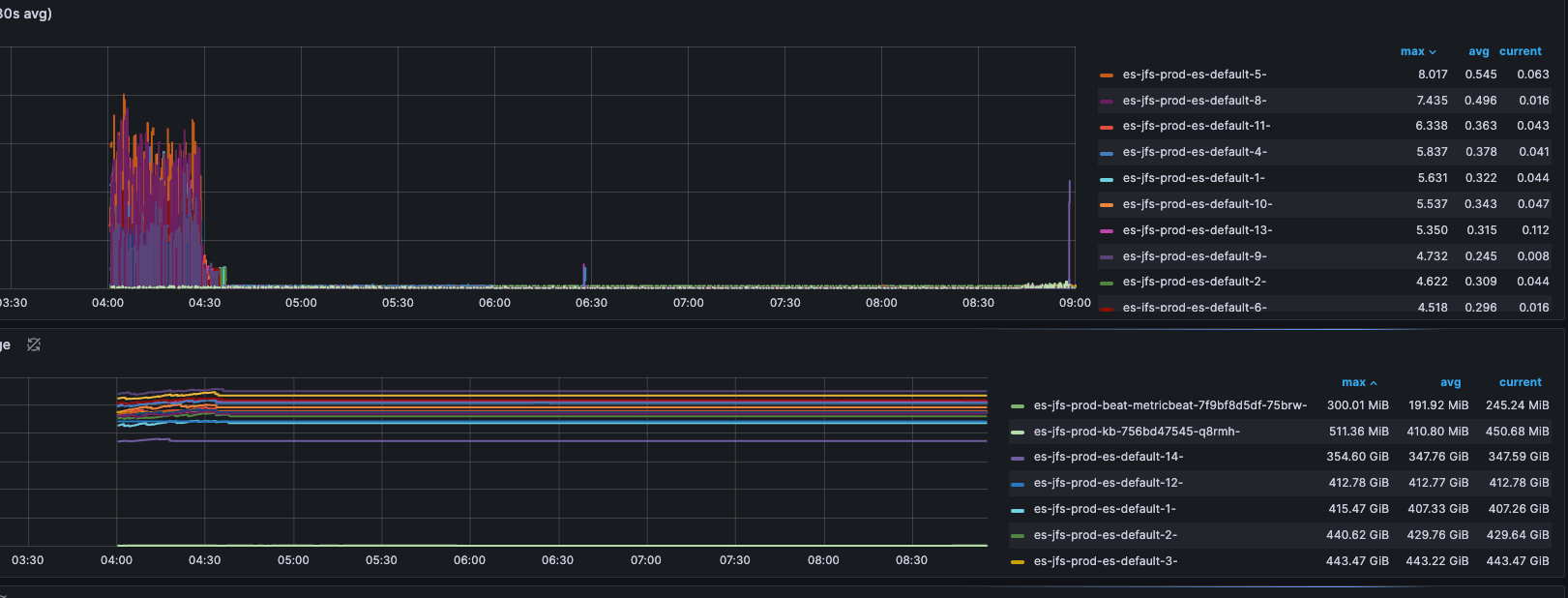
如上图,直到导入数据停止之后,Page Cache 的使用量不再增长,但也并没有立即释放。
4. 解决方案
清理 Cache 是一个解决方案。但无法按照应用的维度来清理 Cache,在主机上清理全部 Cache 会影响其他应用; 同时,从上面的 free 命令输出,可以看到 Cache 太大了,执行 sync && echo 3 > /proc/sys/vm/drop_caches 需要等待很长时间。
另外一个不直接清理 Cache 的原因是,集群上运行的是训练任务,如果训练任务使用了相同的数据集,清理 Cache 会导致缓存失效,增加了训练时间。
只能重启应用了:
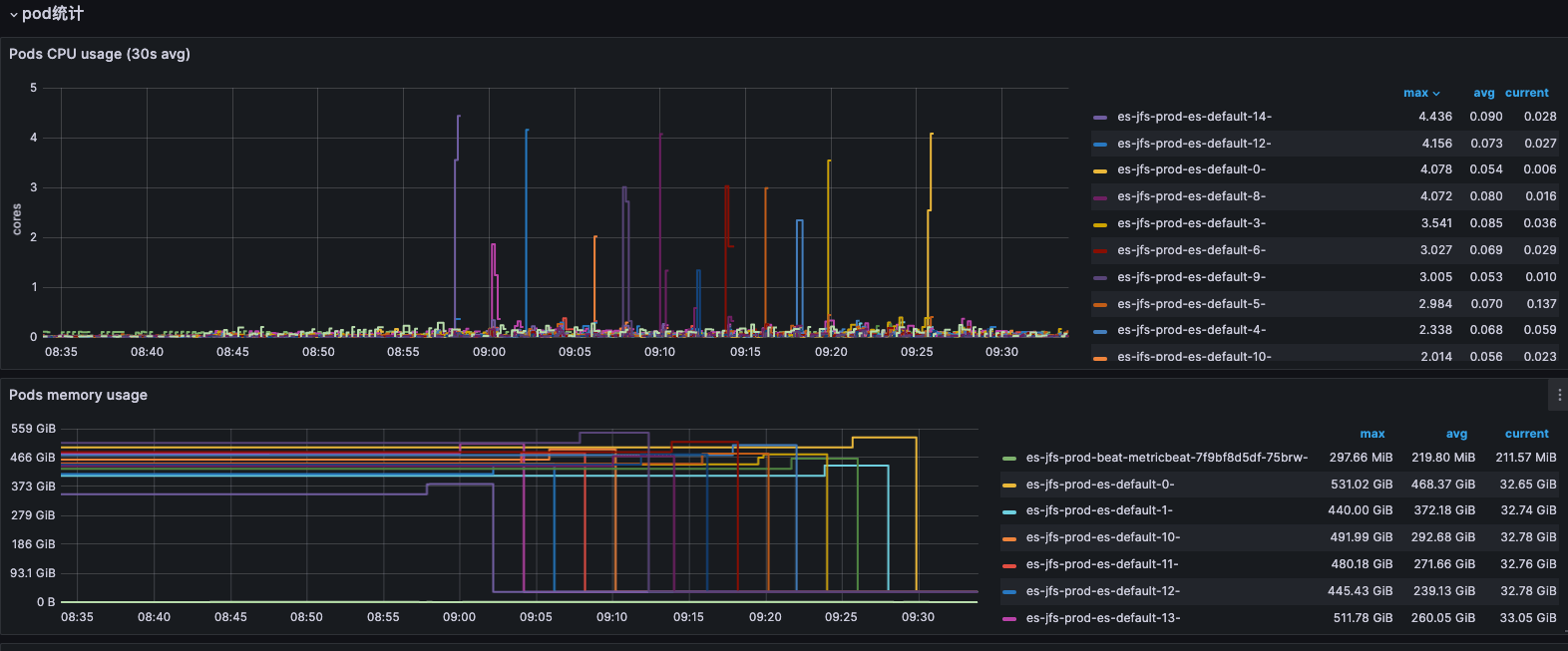
如上图是重启应用之后的内存使用监控,Cache 缓存被释放掉。
这里需要关注的是,怎么样重启应用,有三种方式:
- Delete Pod
- Restart StatefulSet
- ECK Operator Restart
这里推荐修改 ECK 的 Request 配置值来触发重启应用,其他方式容易导致新 Pod 被识别为新的 Elasticsearch Node 触发索引重建。具体什么情况触发、什么情况能够直接复用,我还不能确定。
