本篇内容主要来自内部的一次分享,也是最近工作的一些总结。
1. 常见的故障处理流程
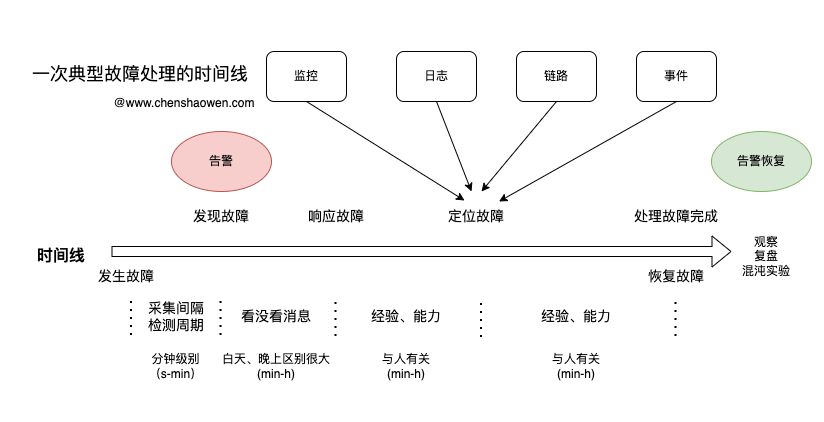
如上图是一次典型的运维异常处理流程。
按照时间线,有如下关键时间点:
- 发生故障
- 发现故障
- 响应故障
- 定位故障
- 恢复故障
发生故障到发现故障,指的是被系统检测到,主要涉及到指标的采集周期、检测周期。如果按照 15 s 的采集周期,检测周期为 1 min,那么发现故障需要时间级别就是几十秒到几分钟级别。
发现故障到响应故障指的是,接收到告警之后,人开始着手处理的时间。白天、晚上的区别就很大,白天工作时间段和非工作时间段区别也很大。晚上,大家都在休息,可能几个小时都没人响应告警;而在白天,运维人员在工作时间段分钟级别就能快速切入,开始定位故障。
响应故障到定位故障指的是,要找出故障的原因。这部分的时间与人的经验、能力密切相关,入职不久的新人,可能得几个小时都不一定能定位到故障;而熟悉基础设施的老运维,可能几分钟就能快速找到问题所在。
定位故障到恢复故障指的是,要修复故障,恢复线上的 SLO。这部分和上面的一部分类似,但对人的能力要求不同,比如程序有 Bug,运维能快速定位故障,但修复还是得研发同学介入。
整体上就是这五个环节,四个时间段,其实后面还需要对 SLO 进行观测、复盘、优化、混沌实验验证等,但不涉及处理故障的流程。
2. 大模型能参与的环节
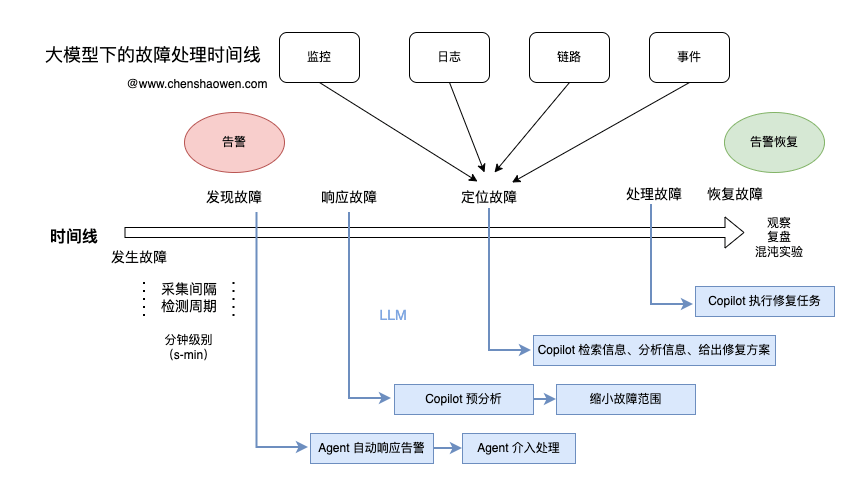
如上图,按照我的分析主要在四个时间点可以介入,分别是发现故障、响应故障、定位故障、处理故障。
2.1 发现故障
发现故障时,人还没来得及响应。
如果大模型能够自动介入,响应告警,能获得最快的响应速度,获得最大的收益,极大缩短平均故障处理时间 MTTF。
但发现故障时,立即让大模型介入也是最难的。难点就在于,需要开发一个 AI Agent 自动的响应告警信息,自动的收集观测的指标,自动调用平台接口,甚至登录机器尝试处理故障,验证是否被修复了,循环往复。
如果你写过代码或者智能体就会知道,这件事挺难的,而如果你觉得很简单,可能就是高估了大模型的智能水平,低估了现实问题的复杂度。
2.2 响应故障
响应故障时,大模型如果能立即对故障进行初步的分析,缩小故障的处理范围有利于加快定位故障的速度。
大模型预分析,依赖于平时的故障处理资料,这需要我们在每次发生故障时,详细地记录和分析故障的各个方面。
只有具备足够的故障数据根因数据积累,才能有效借助大模型缩小故障范围。
2.3 定位故障
现在的可观测性又扩充了,新增了事件,加上之前的监控指标、日志、链路,数据源是多了,但是每次定位故障时,需要查询的平台也多了。
大模型可以帮我们有效缩短查询这些可观测性指标的时间。
同时,根据一些关键字,还能检索文档库,分析故障原因,给出一些修复方案,节省我们上网检索的时间。
2.4 处理故障
大模型也可以用来直接处理故障。
回忆一下,我们经常是怎么处理故障的。重启一下 Deployment、重启一下 Kubelet、调整一下路由配置、换一个节点试试等。这些通常就是一条命令、一次接口调用、一次按钮点击。
让大模型帮我们执行这些操作,非常省时省事儿。
2.5 小结
大模型能够参与的环节其实很多,但从难易程度上看,大模型越早介入难度越大,越晚介入易于实现。
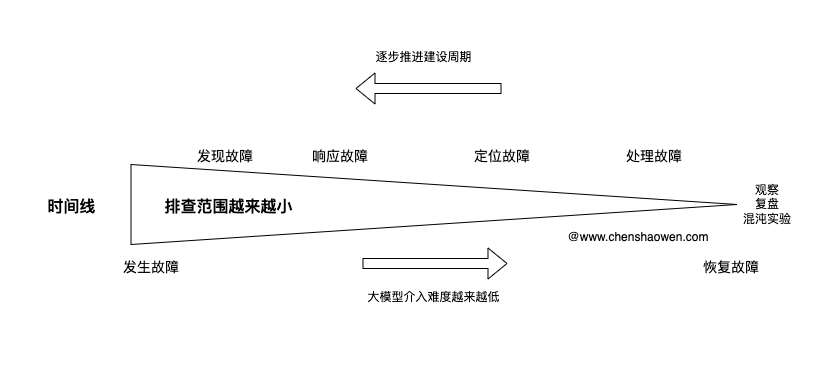
故障早期涉及的范围太大,大模型难以有效捕获到故障的关键根因,而人的经验、灵活性、自主学习能力会体现出优势。
最终落地大模型却要反着来,先用大模型介入后期的处理,逐步积累相关的文档和案例,再将介入的时间点往前推移,直至能够完全实现 AI Agent 自动化的响应故障。
3. 使用大模型处理故障时的挑战点
3.1 文本如何转换为运维操作
我们熟知的大模型服务,典型的输入和输出都是文本、图片、视频。
如果将这些静态的输出,转换为一个具体的操作,一个命令的执行,一个运维的操作,这是我们首先要面对的问题。
3.2 大模型提取的信息不稳定
对于程序来说,确定性是非常重要的,但大模型的魅力就是不确定性、多样性。着手开始写大模型应用很容易遇到这些问题:
- 大模型不理解意图,频繁道歉
- 输出的格式不对
- 输出的参数缺失
- …
类似的问题会有很多,我们通常会从以下几个方面破局:
- 提示词
- 重试
- 微调模型
当然,这次我想提的另外一个关键点,从应用设计的层面来解决。
3.3 怎么快速接入场景
快速验证、快速迭代应该深入每个工程师的基因中。怎样快速对接上各种场景,让我们的方案看起来不那么离谱,甚至感觉有点效果很重要。
这里我选的就是日常的一些琐事:
- 处理告警事件
- 辅助日常运维
但这两大类事情的子项非常多,几十种,甚至上百种场景,我想到的是插件编排的思路。如果能抽象出原子操作,拼接原子构成流水线,就能够覆盖无数种场景。
4. 落地关键技术 - Ops 简介
每个领域可能都需要一个类似 Ops 的项目,提供大模型驱动领域的能力。下面对 Ops 进行简单介绍。
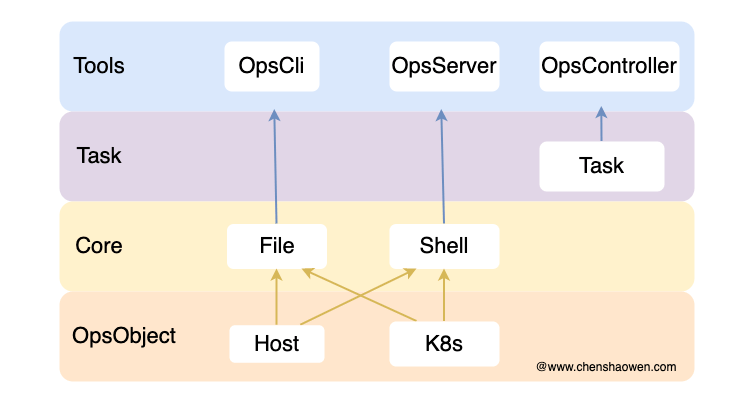
- OpsObject
通过 CRD 存储操作对象,管理集群、主机对象。
- Core
核心操作,实现文件分发和脚本执行的能力。
- Task
封装、组合各种操作,轻量级的编排能力。
- Tools
对外提供三种操作入口
Ops 项目是对接运维能力的关键。我之前的文章中已经多次介绍,感兴趣的话可以前往 https://www.chenshaowen.com/ops/ 查看详情。
4.1 使用示例 - 查看对象
- 查看运维对象

可以看到集群的节点数、证书过期剩余天数等关键信息。
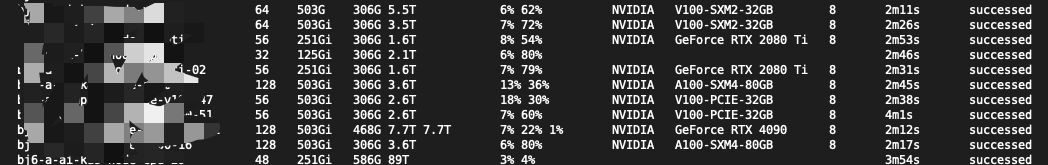
可以看到节点配置、GPU 卡的亚实时状态。
4.2 使用示例 - Opscli
- shell 用于在主机上执行脚本
- file 用于在主机与 S3、文件服务、镜像之间传输文件
- task 用于编排多个 shell\file 操作
- 支持仅提供 kubeconfig 凭证,在指定节点上执行命令
- 也支持 Kubectl 中的 SA 鉴权
4.3 使用示例 - Web UI
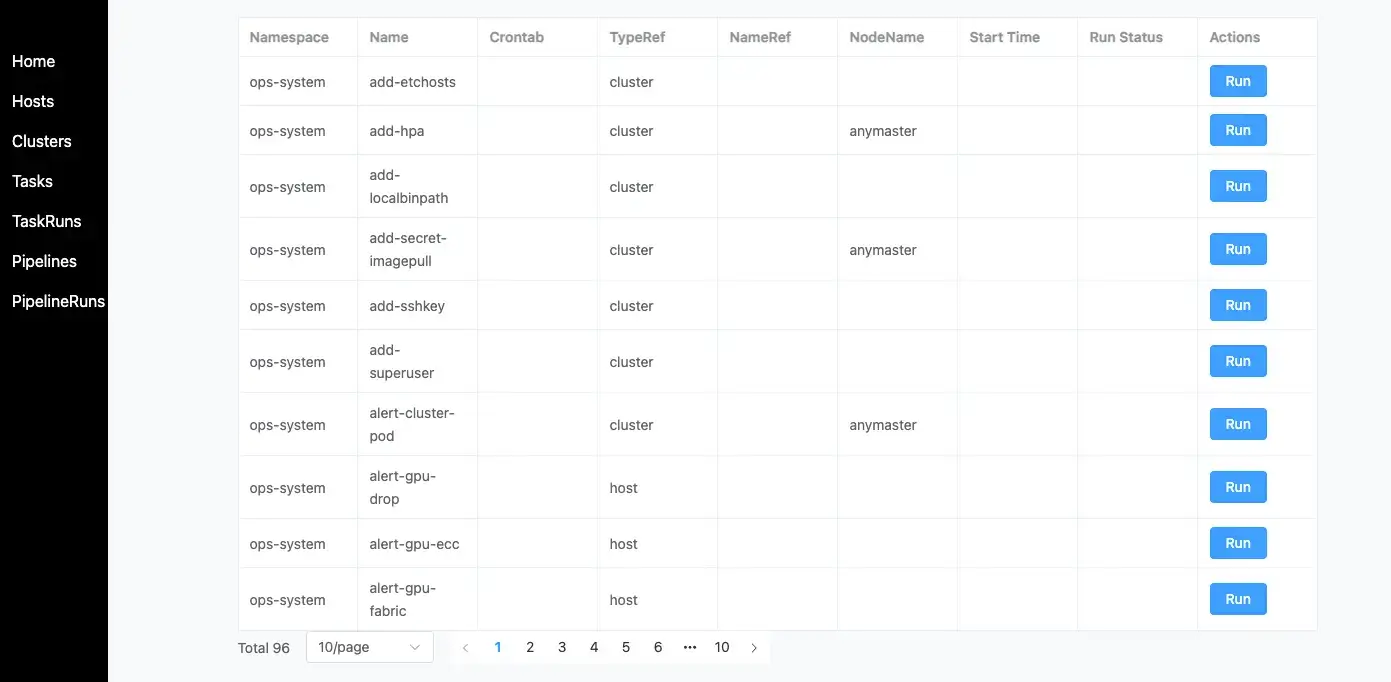
通过更简单的方式使用 Ops 的核心能力:
- Server 提供接口能力
- Web 有提供一个简单管理的 UI
4.4 使用示例 - Task
Task 提供模板的能力,只需要先定义一个任务。
| |
接着在 TaskRun 中引用这个任务就能够执行。
| |
5. Copilot 的设计
Copilot 是我们目前落地大模型处理运维故障的主要形态。通过交互对话的方式,让大模型参与到故障处理的过程中,按照前面的思路,先介入故障处理的后期,再落地前期,采用逐层积累、推进的策略。
5.1 关键步骤
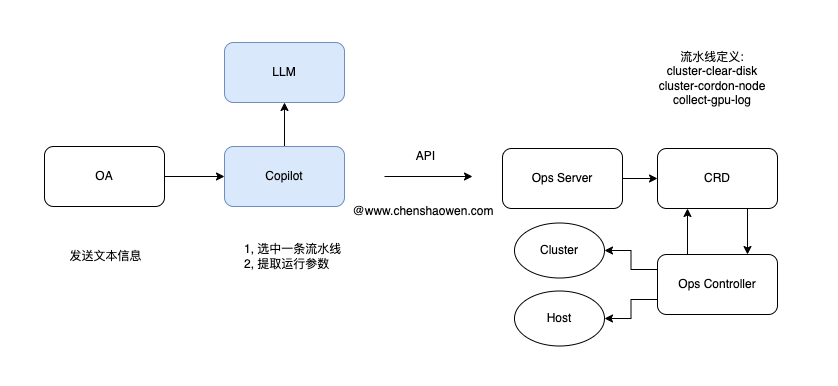
核心的思路:
- 通过 Ops 项目对 Copilot 提供运维的操作能力
- 通过流水线 pipeline 提供操作场景对接能力
核心的步骤:
第一步,大模型帮我们选择一条流水线
第二步,大模型帮我们从故障的上下文中提取运行流水线的参数
这与 function_call 的功能类似,只不过调用的不是 function 而是 pipeline。使用 pipeline 对接场景的好处多多,不仅能够处理更加复杂的任务,还能不被模型功能限制。
目前只要支持 OpenAI 接口的大模型,都能够对接上 Copilot 的 pipeline。只不过由于没有经过运维故障处理领域的微调,使用的模型参数量不能太少,对理解能力有一定要求。
5.2 流水线的设计
流水线的设计目标是:
- 便于大模型识别意图,选中一条流水线执行
- 便于扩展,覆盖更多场景
- 便于大模型自行组装 tasks 形成新的 pipeline,为实现 AI Agent 提供可行路径
我很熟悉 CICD 等编排系统,很容易就用代码写出这个 pipeline 对象和具体执行逻辑。
目前已经定义了:
- task 95 个
- pipeline 20 个
同时,由于 task、pipeline 都是 CR 对象,只需要编写 Yaml 就能够快速对接场景,十分方便。
最终提交给大模型的输入是这样:
| |
5.3 变量的设计
变量的设计如此重要,只有当你真正写过大模型应用时,才会由此体会。
首先是参数的定义:
- 默认值
- 描述
- 正则
- 是否必须
- 枚举
- 示例
- 固定值
接着是参数的优先级:
- task 固定值
- pipeline 固定值
- 运行提取值
通过变量的设计,我们可以获得如下好处:
- 通过变量定义提高抽参数准确性
- task 固定值提高执行成功率
e.g.只运行在 master 节点 - pipeline 固定值提供敏感信息
e.g. 上传 S3 的 ak\sk 值
下面是我提交给大模型的输入:
| |
6. 主动发现故障,让飞轮转起来
如果只是被动等待故障,要到猴年马月才能积累足够的数据,最好的办法永远是主动出击。
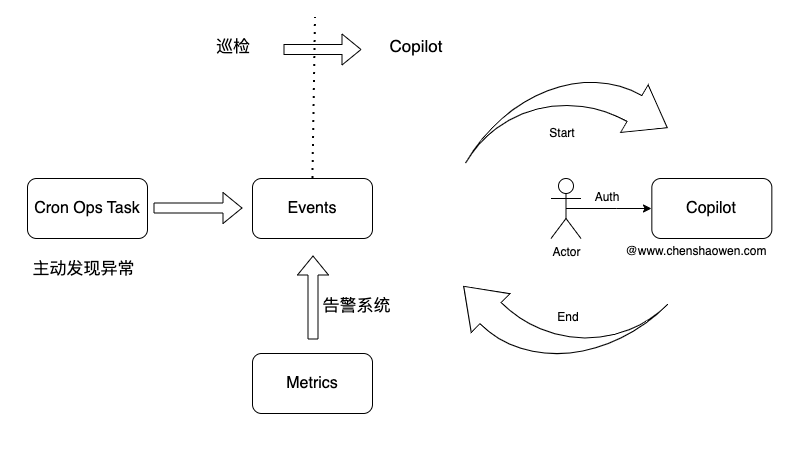
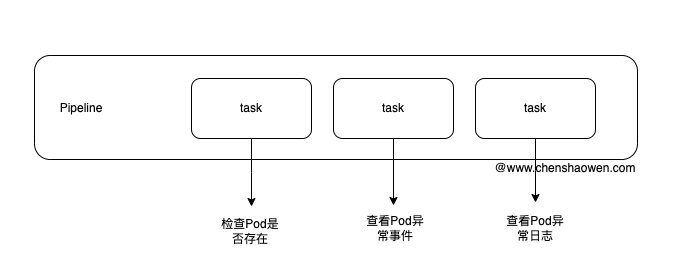
巡检能够主动的发现一些潜在问题,在故障发生之前,提前预警。
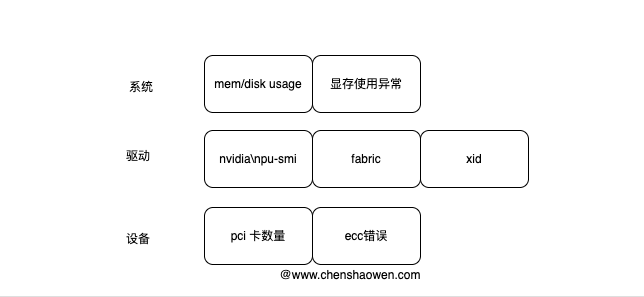
目前我们的巡检已经涉及多个方面,设备层、驱动层、系统层等。新加入集群的节点也可以自动加入巡检中。
巡检的配置也非常简单,还记得上面的 TaskRun 对象吗。
| |
只需要在 TaskRun 中加上 crontab: 0 0 * * * 就可以开始周期性的执行了,这个示例中就是每天八点清理磁盘。而巡检任务只需要在 Task 中写了一些巡检的逻辑,并触发告警通知、推送预警事件即可。
7. 典型案例
可能上面提到很多内容,还缺少一个直观的感受,下面我就来介绍一个典型的案例。
AI 加速卡工作在高温环境中,经常会有各种异常和报错。不同于 CPU 会大幅降频自我保护,AI 加速卡会掉卡(系统层、驱动层识别不了硬件的状态),直接无法使用。千卡训练,平均每天至少一张卡异常。
当 GPU 掉卡时,就需要报修,让云厂的工程师在现场解决,下面是传统的报修流程。
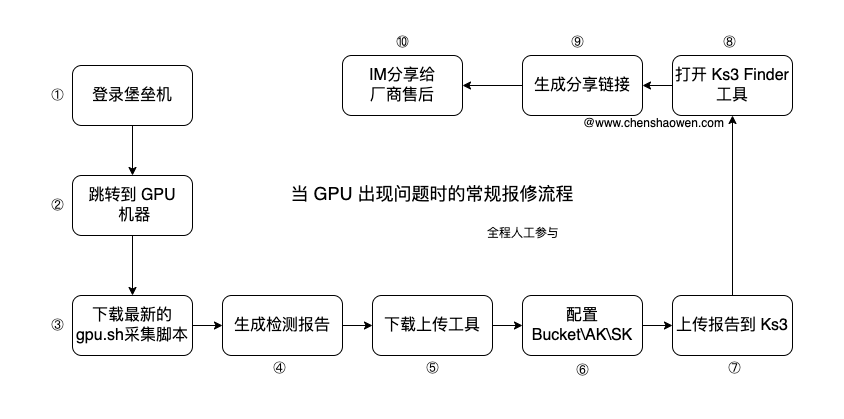
现在只需要在 IM 中 at Copilot 就行。

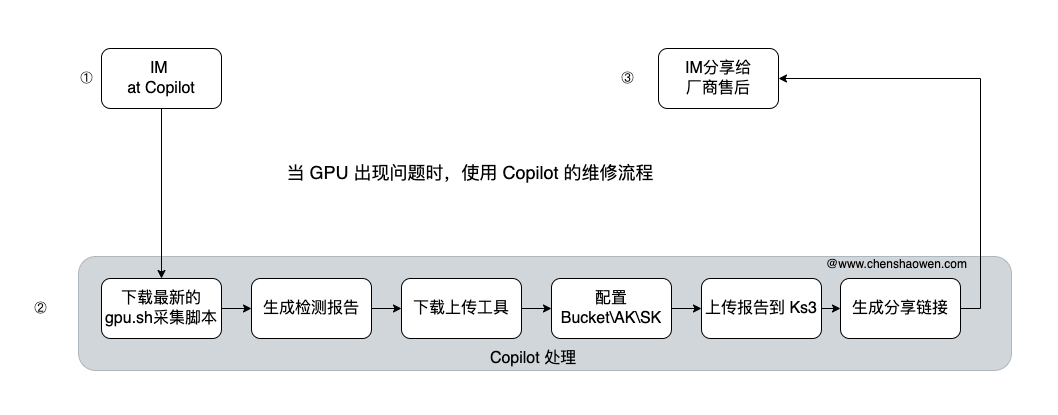
处理时间从几十分钟减少到了几分钟,同时也增强的安全性,避免 AK/SK 信息泄露。
除了这个在流程、时间上能极大提高效率的案例之外,我还比较看中的是,现在处理故障不受时间、是否能远程办公等条件约束,随时随地都能处理。
8. 总结
本篇介绍了我在使用大模型处理运维故障的一些实践,希望对大家设计和开发大模型应用有所帮助。主要内容如下:
- 故障处理流程的时间线以及大模型能参与的环节
- 大模型几乎能参与全部的故障处理环节,包括故障的发现、响应、定位、处理
- 着手使用大模型处理故障时,可以从距离解决故障最近的环节开始,逐步向前推进
- 如果你也在从事运维相关的工作,可以试试 https://github.com/shaowenchen/ops 项目
function_call是一种思路,不要局限在function还可以是 pipeline、workflow 等任意可编程对象- 开发大模型应用时,对变量的描述极其重要
