1. 基于对象存储的数据交付
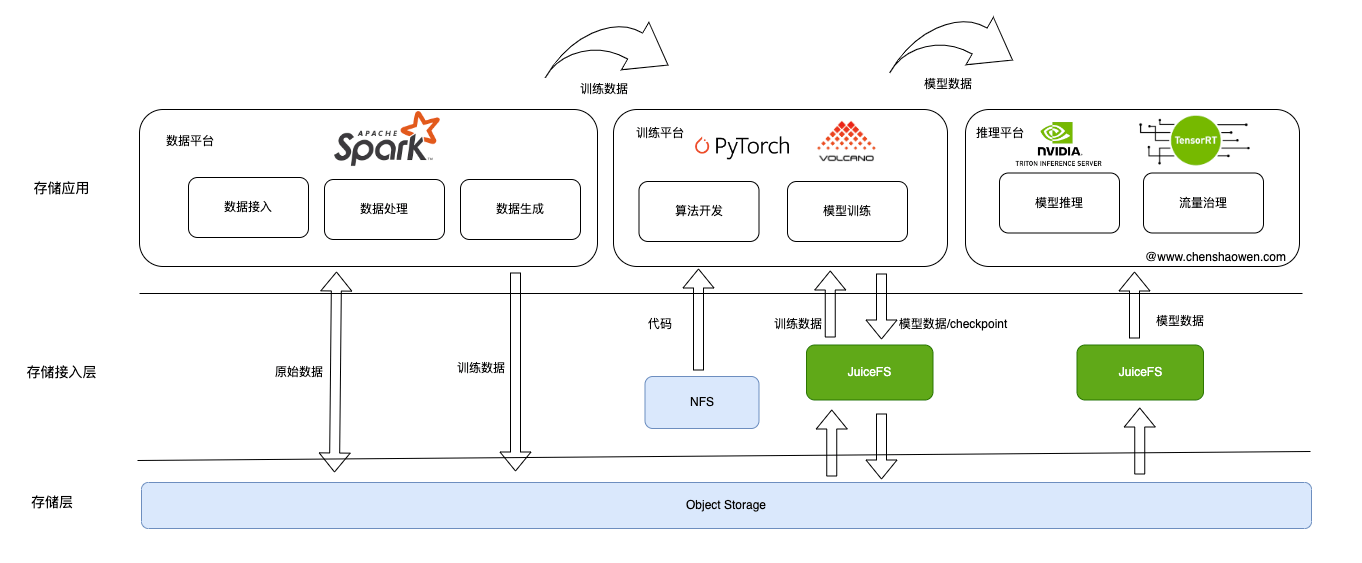
如上图,在模型研发过程中,主要涉及三个子平台,分别是:
- 数据平台
数据平台主要负责数据相关的管理,比如: 数据接入、数据处理,最终生成训练所需的数据。
数据平台将原始数据存储到对象存储中,在处理时,从对象存储中获取数据,进行处理,完成之后存储到对象存储中。
- 训练平台
训练平台主要负责模型的训练,比如: 提供模型的开发环境,支持模型的分布式训练。
训练平台会给算法同学提供一个带有 AI 算力卡的 Jupyer 环境,以支持算法同学的线上开发和调试。他们将代码存储在实时性高的存储设备中,通过挂载的方式访问 checkpoint、模型等文件。
启动大型分布式训练任务时,数据会被逐层预热直至 AI 算力卡的显存中,然后训练模型,最终得到模型。
- 推理平台
推理平台主要负责模型的上线、流量的管理,比如: 模型的量化、模型的转换、模型的部署等。
推理平台从对象存储中获取模型,开启工作流,部署模型并实现推理流量的治理。
数据平台、训练平台、推理平台通常有不同的技术负责人,不能强求各平台使用统一的数据定义、使用的规范。
因此这里强调的是数据交付,我们只需要定义好数据交付,至于各个平台内部如何实现,选择怎样的挂载方式、加速组件等,都由各个平台自己决定。
从成本、性能、交付便捷性等方面考虑,基于对象存储的数据交付是一个非常好的选择。很多数据湖方案的底层也是基于对象存储。
2. 数据平台
虽然 AI 加速卡擅长数据处理,但数据平台通常并不会使用这些昂贵的设备对数据进行处理。
AI 任务主要占用的是 AI 算力卡资源。在我们线上的集群中,GPU、NPU 卡的显存使用率经常能达到 90%,但节点上的 CPU、Memory 资源使用率却只有 10% 左右。
而加速计算节点又是高配的机器,它们的通常配备了几百 GB、甚至几个 TB 的 Memory,200 核心起步的 CPU 计算能力。这意味着,在加速计算节点上,我们还有大量的资源可用。
数据平台的工作负载非常适合与 AI 任务进行混合部署。
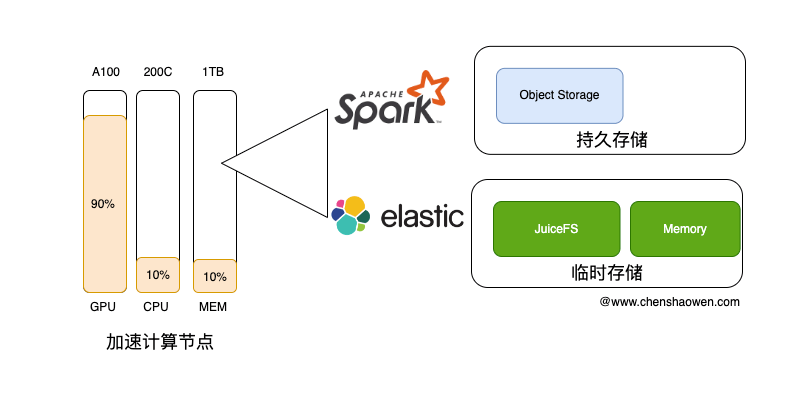
如上图,数据平台的存储主要分为两类:
- 持久存储,比如录入的数据、训练需要的数据等
- 临时存储,比如处理数据过程中加速的数据、支撑数据集全文检索的 ES 存储卷等
3. 训练平台
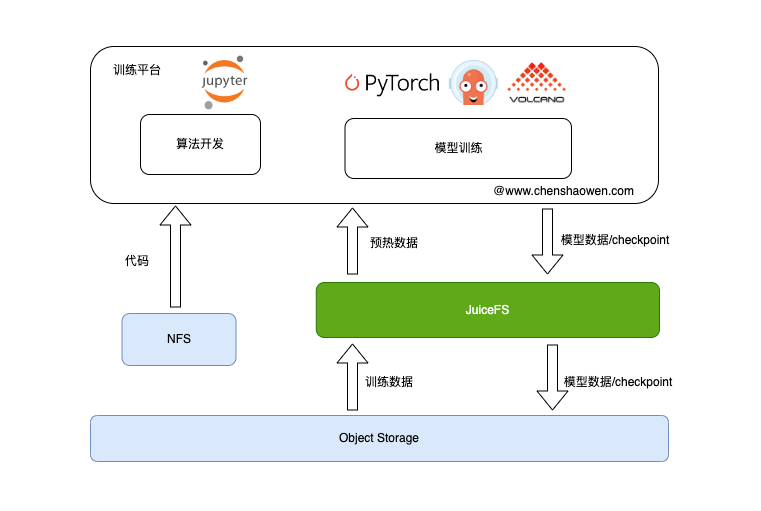
如上图,在训练的过程中主要涉及三个存储交互:
- 算法开发,存储算法同学的代码
代码是小文件,同时对实时性要求比较高,不适合存储在 JuiceFS 中,可以采用 NFS 存储,通过不同目录进行隔离区分个人和团队。
- 训练数据,存储训练数据
训练数据的特征时,小文件特别多,对元数据的访问速度要求比较高,可以采用 JuiceFS 多区企业版。
- 模型数据、Checkpoint 数据
存储 Checkpoint 时,训练任务处于暂停状态。Checkpoint 的存储速度会影响训练的效率。
模型数据、Checkpoint 数据的暂存,也应该采用 JuiceFS,但可以降级为单区的企业版或者社区版。
训练完成之后,我们应该设置一个归档任务,将训练过程中的模型、数据等数据存储到对象存储中。
JuiceFS 应该作为一种临时存储,作为加速层,不应该长时间存储数据。
4. 推理平台
我们通常在一个区域训练,但是需要在多个区域进行推理。
进行多区推理的原因可能有:
- 上层服务在多云部署,需要就近推理
- 单个云的 AI 算力卡资源不足
- 多云高可用
但这也带来了新的问题,模型怎样在多个云区域进行分发。
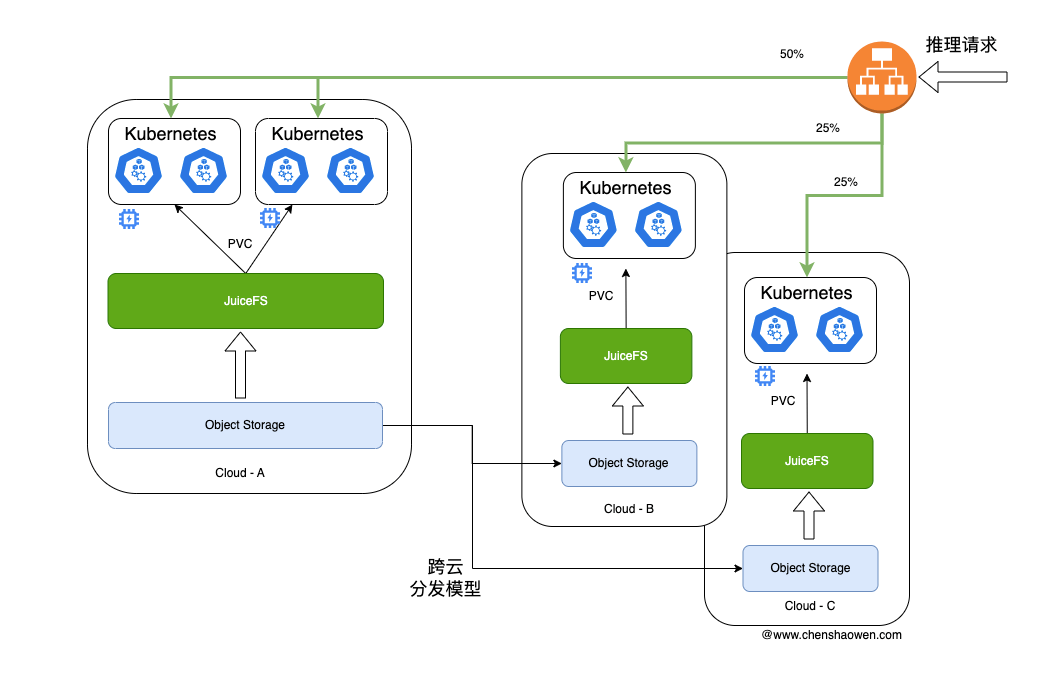
如上图,模型的原始数据应该存储在对象存储上,通过公网或者专线进行模型的跨云分发。比如,从阿里云的 OSS 同步模型数据到腾讯云的 COS,公有云的对象存储同步速度比较快。
在每个区域中,借助 JuiceFS 单区企业版或者社区版,将模型加载到 JuiceFS 通过 PVC 挂载到集群的推理 Pod 中,实现模型的推理。
在同一个区域中的多个 Kubernetes 集群,可以共用一个 JuiceFS 存储。
