1. Parameter Server 架构
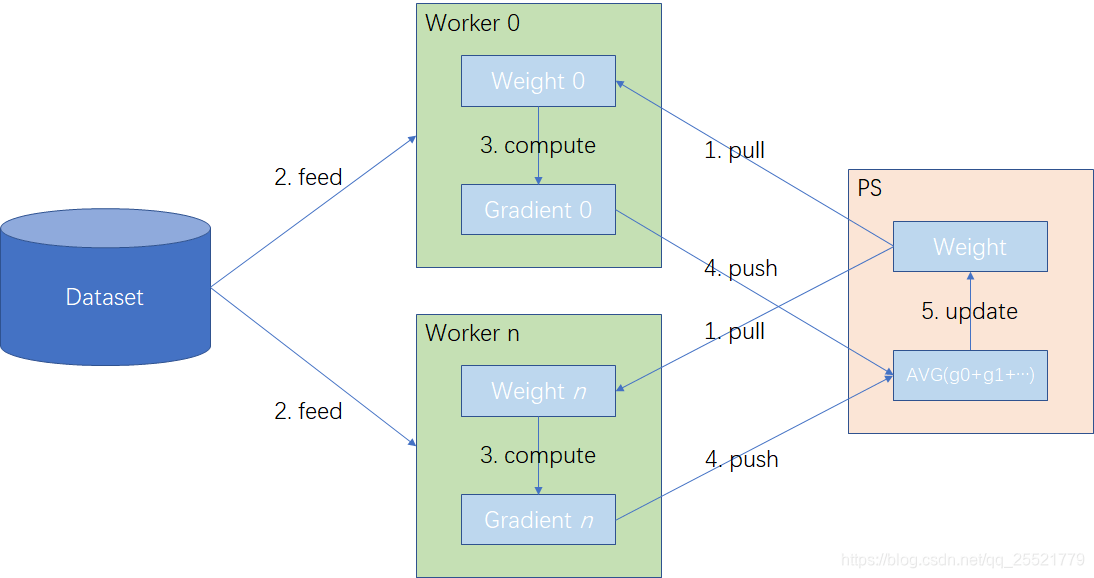
在 Parameter Server 架构中,集群中的节点被分为两类,参数服务器节点(Parameter Server)和工作服务器节点(Worker)。
1.1 Parameter Server
Parameter Server 用于存放模型的参数。
每个参数服务器节点负责管理和更新模型的一部分参数,而每个工作节点则只处理与其对应的数据子集。
1.2 Worker
工作服务器节点负责执行模型的训练任务。训练的数据被分配给多个工作服务器节点。每个工作服务器节点独立进行前向和后向计算,最终产生梯度信息。
1.3 训练过程
- 初始化,所有参数服务器节点完成模型权重的初始化。
- 权重获取,工作服务器节点从所有参数服务器节点中,pull 对应的权重。
- 前后向计算,工作服务器节点执行前向和后向计算,生成梯度。
- 梯度上传,工作服务器节点将计算得到的梯度 push 到相应的参数服务器节点。
- 权重更新,参数服务器节点在接收到所有工作服务器节点的梯度后,进行汇总并更新模型权重。
- 重复迭代,继续执行第 2 到第 5 步骤,直到达到收敛条件或结束训练。
1.4 结构的维护
Parameter Server 失败后的处理
- 重新分配参数,故障的参数服务器节点的参数将被重新分配给其他可用的服务器,以保持模型的完整性。
- 动态负载均衡,系统会自动调整负载,确保参数在各服务器间均匀分布,防止过载。
- 训练的继续进行,工作服务器会与新的参数服务器重新连接,继续进行模型训练。
Worker 失败后的处理
- 任务重分配,失联的 Worker 的任务会被重新分配给其他可用的 Worker,避免计算资源浪费。
- 渐进收敛策略,剩余 Worker 可以在少量数据上继续训练,避免长时间中断。
- 故障恢复,如果故障的 Worker 恢复,系统会将其重新加入训练并继续未完成的任务。
新的 Worker 加入
- 数据重新分配,新 Worker 加入后,系统会将部分训练数据分配,确保负载均匀。
- 梯度同步,新 Worker 会从参数服务器获取最新权重,并与其他 Worker 进行梯度同步。
- 动态扩展,新 Worker 能够无缝融入训练流程,提升整个系统的计算能力。
1.5 框架支持
TensorFlow 原生支持 Parameter Server 架构,提供了
tf.distribute.Strategy来实现分布式训练。PyTorch 可以使用 torch.distributed 包或其他库(如 Ray 和 Horovod)来实现 Parameter Server 训练。
1.6 适用场景
- 大规模推荐系统
在推荐系统中,模型参数可能包括用户偏好和物品特征等,这些参数量可能非常庞大。使用 Parameter Server 可以有效地管理和更新这些参数。
- 自然语言处理(NLP)
在训练大型语言模型,如 BERT 或 GPT 时,Parameter Server 可以帮助分布式地存储和更新模型的词嵌入和层间权重。
- 图像识别
在训练用于图像识别的深度神经网络时,如卷积神经网络(CNN),Parameter Server 可以分布式地处理大量的滤波器权重。
- 大规模线性回归
在处理具有数百万特征的线性回归问题时,Parameter Server 可以分布式地存储和更新权重矩阵。
- 实时大数据分析
在需要实时更新模型参数以响应快速变化的数据模式的场景下,Parameter Server 架构可以提供所需的灵活性和扩展性。
2. AllReduce 架构
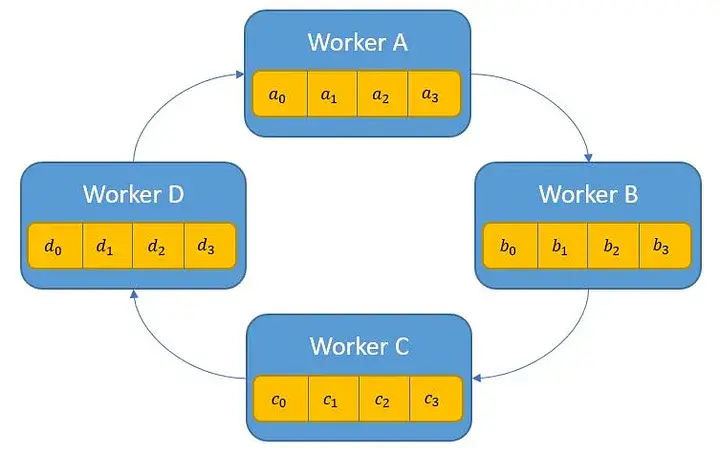
2.1 通信环的建立
- 初始化 Rank
每个 Worker 都会被分配一个唯一的 Rank(通常为整数,表示 Worker 的身份和顺序)。
- 建立初始通信环
根据 Worker 的 Rank,系统将每个 Worker 与其左右相邻的 Worker 进行配对,形成一个环形通信拓扑结构。假设有 N 个 Worker,则每个 Worker i 会与 i-1 和 i+1 进行通信(其中 i=0 的左邻居为 N-1,i=N-1 的右邻居为 0),从而形成一个封闭的通信环。
2.2 训练过程
- 梯度分割
每个 Worker 将自己计算得到的梯度切分成多个块(通常与 Worker 数量相等)。
- 梯度交换
每个 Worker 将自己持有的第一个梯度块发送给右邻居 Worker,同时接收从左邻居 Worker 传来的第一个梯度块。这一过程进行多轮通信,每一轮中,Worker 发送下一个梯度块并接收新的梯度块
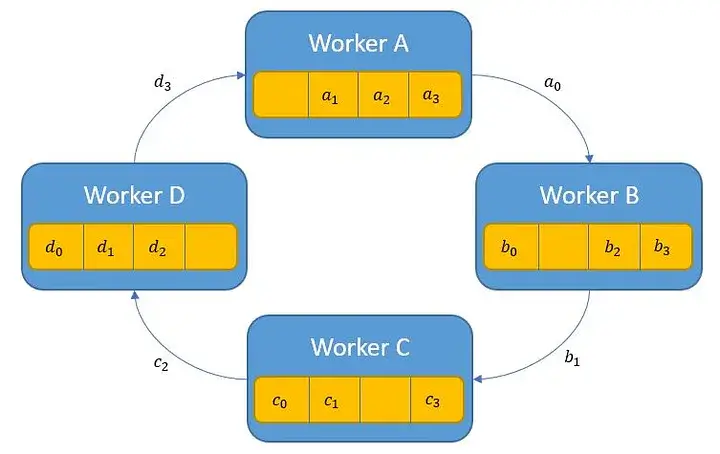
- 梯度累加
在每一轮通信中,Worker 不仅接收新的梯度块,还会将其与之前累加的梯度块相加,从而逐步在所有 Worker 中汇总梯度
- 广播最终结果
当所有梯度块都被交换并累加完毕后,最终的累加结果会通过继续环形通信广播回每个 Worker。此时,每个 Worker 都拥有完整且同步的全局梯度信息
2.3 结构的维护
Worker 失败后的处理
- 检测失联,剩余的 Worker 会自动检测到失联的 Worker,并触发故障处理机制
- 重新分配 Rank,系统会自动重新分配故障 Worker 的 Rank,并更新通信拓扑
- 重建通信环,失联 Worker 的左右邻居将重新建立连接,形成新的环形拓扑
新的 Worker 加入
- 插入通信环,新 Worker 加入后,系统会根据其 Rank 将其插入现有的通信环
- 建立连接,新 Worker 会与其左右邻居建立通信连接,从而扩展环的结构
通信环的同步与恢复
- 状态同步,所有 Worker 在新的通信环建立后,会重新同步之前的梯度累加状态
- 继续训练,同步完成后,系统会继续进行后续的训练步骤,确保训练的稳定性和一致性
2.4 框架支持
- PyTorch 原生支持 AllReduce 操作,提供了
torch.distributed模块。 - TensorFlow 原生支持 AllReduce,通过
tf.distribute.Strategy模块使用 MirroredStrategy 策略使用 NVIDIA NCCL 进行 AllReduce 操作
2.5 适用场景
- 深度学习模型训练
在使用 TensorFlow 或 PyTorch 等深度学习框架训练大型神经网络时,AllReduce 算法可以高效地在多个 GPU 或 TPU 之间同步梯度。
- 分布式优化算法
在实现分布式版本的随机梯度下降(SGD)或其他优化算法时,AllReduce 用于确保所有计算节点在每次迭代中使用相同的全局梯度估计。
- 多任务学习
在多任务学习场景中,不同的任务可能在不同的计算节点上进行训练,AllReduce 可以确保所有任务共享相同的模型参数更新。
- 强化学习
在分布式强化学习中,多个智能体(agents)可能需要同步它们的经验或策略更新,AllReduce 算法可以在此过程中发挥作用。
- 大规模图计算
在处理大规模图数据,如社交网络分析或网络流量分析时,AllReduce 可以用于在多个计算节点间同步图的嵌入或节点特征。
- 科学计算和模拟
在需要大规模并行计算的科学领域,如气候模拟、物理模拟等,AllReduce 可以用于在多个计算节点间同步模拟状态。
